未标注目标语料是否均适合用于跨语言学习?『基于对抗判别器高效利用未标注语料的跨语言NER算法AdvPicker』
(再过几个小时今年的 ACL 就要来了,赶在 ddl 之前,
简单介绍一下韦乐,我,千惠,Börje,Yi Guan 等人在 ACL21 上的这篇工作。
AdvPicker: Effectively Leveraging Unlabeled Data via Adversarial Discriminator for Cross-Lingual NER (ACL-IJCNLP 2021)
✍️Weile Chen, Huiqiang Jiang, Qianhui Wu, Börje F. Karlsson, Yi Guan.
👨💻 Code in Github
Motivation
事实上,经济实力注定会影响所有科技技术发展的进程。 对于如今大火的标注资源敏感型的一系列深度学习任务,这种冲突更为明显。 迁移学习、自学习、对比学习等方法有效解决了很大一部分问题,但这些方法往往需要大量数据,且仅适用于少量任务或者不能完全解决下游任务问题。
而在拥有丰富高质量的英语语料下(其实还是少数 domain),FLAT NER 任务已经能够做到比较高的准确率,如何将这种能力合适的迁移到其他低资源,甚至无资源的目标语言中,是一个很有挑战性的问题。 之前的工作按照算法设计角度,可以分为着重构造一个能够扑捉跨语言特征的模型的 Feature-based methods 和着重构造目标语言数据标注的 Labeling-based methods。 其中,Feature-based methods 可以通过 mBERT、Meta-learning、Adapter 等方式实现,Labeling-based methods 又可分为 Soft-label 和 Hard-label,可通过预训练好的翻译模型,也可通过利用 Distillation 来实现。
但是这些方法都假设所有未标注语料都具有这种跨语言特性,都适合来做迁移学习,这是一个开放的问题。 我们直觉告诉我们就如同高质量标注数据也存在大量噪声一样(可以用 Co-teaching 的方式来解决),未标注目标语言数据也不应该全部适用跨语言训练中。
本文的目标是设计一个能够与模型蕴含的与语言无关特征一致的数据判别器。
AdvPicker
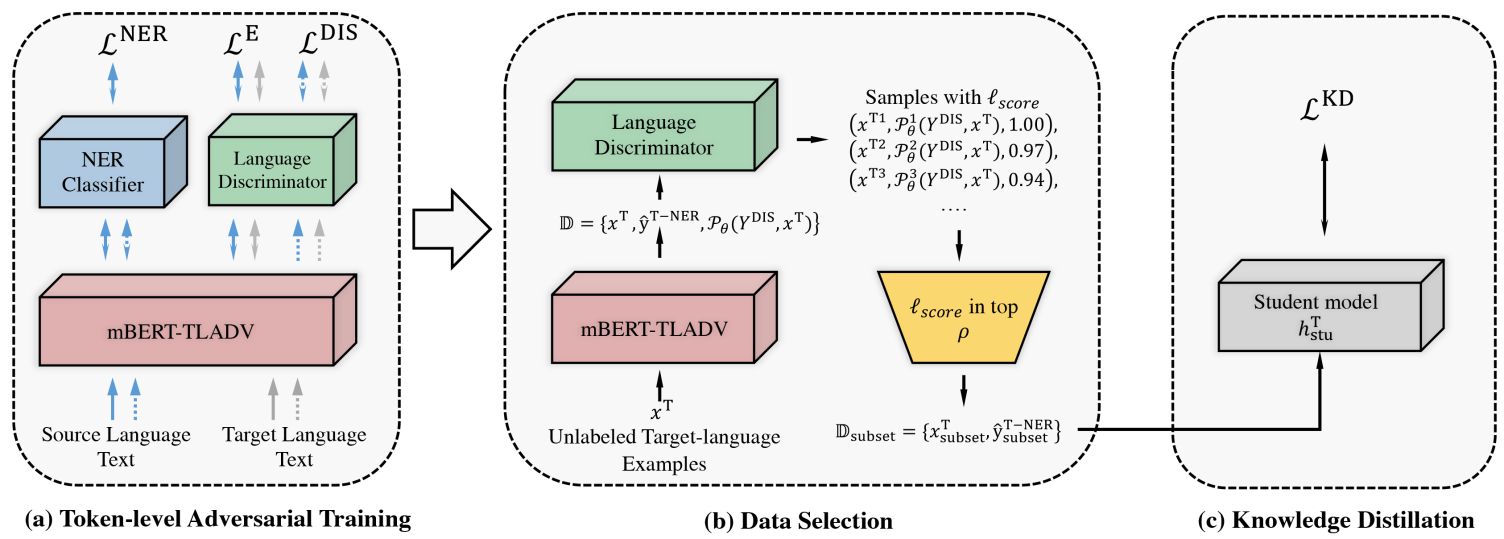
如何去构造这样的一个判别器?既然我们的目标是扑捉 Language-independent 的信息,那么就应该让模型避免拥有 Language-specific 的能力。
这种能力又如何来衡量呢?首先,我们想到的是如果 freeze 掉模型的参数,在模型下游加一个 FFN 去做判断语料来源任务(2 分类任务,0-源语料,1-目标语料),如果模型能很容易判断这个任务的话,就说明模型对于 Language-specific 的特征学习的很好。
简单在 mBERT 和源语言上 Fine-tune 的 mBERT-ft 两个模型上进行测试,如下表所示。
\begin{array}{c|cccc} \hline & \textbf{de} & \textbf{es} & \textbf{nl} & \textbf{Avg} \\ \hline \text{mBERT} & 99.08\% & 99.66\% & 98.98\% & 99.24\% \\ \text{mBERT-ft} & 98.38\% & 98.66\% & 97.27\% & 98.10\% \\ \text{mBERT-TLADV} & 79.62\% & 82.89\% & 77.45\% & 79.99\% \\ \hline \end{array}
上述实验说明(先忽略第三行),在默认或者 Fine-tune 情况下,模型拥有极强的 Language-specific 能力。 这也就导致了直接拿来做迁移学习的话,会导致 Student Model 学习到的基本上都是 Langauge-specific 特征,这不是我们想看到的。
如何去降低这种源模型对于 Language-specific 特征过于敏感的情况,我们想到的是利用对抗学习+多任务,使得源模型在源语言上做 Fine-tune 的同时, 式$(\ref{equ:ner})$,对抗的去学习一个 Token 粒度的语言判别器(Token-levl Adv, TLADV), 式$(\ref{equ:dis})$,即模型流程图的图(a)部分。
整体目标就是使得模型即学习到 Task-specific 的 NER 特征,又能降低学习源语言 Specific 的特征。
\begin{equation} \mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{NER}}) = \text{softmax}(\boldsymbol{W}^{\text{NER}}\boldsymbol{h} + \boldsymbol{b}^{\text{NER}}) \label{equ:ner} \end{equation}
\begin{equation} \mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{DIS}}) = \sigma(\boldsymbol{W}^{\text{DIS1}}\text{ReLU}(\boldsymbol{W}^{\text{DIS2}} \boldsymbol{h})) \label{equ:dis} \end{equation}
其中$\boldsymbol{h} = {\boldsymbol{E}}(\boldsymbol{x})$为 Encoder, $\boldsymbol{W}^{\text{x}}$为可学习参数, $\mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{X}})$为任务输出概率估计。
🤦 一开始想的挺美好的,但是 Adversarial Learning 的调参过于玄学,此处省略无数实验 work,也许以后可以用 NNI 这种来完成这种工作。
\begin{equation} \mathcal L^{\text{E}} = - \frac{1}{N} \sum_{i \in [1, N]} \log{\mathcal{P}_{\theta}(Y^{\text{DIS}}_{i} = {\widetilde{y}}^{\text{DIS}}_{i})} + \log{\mathcal{P}_{\theta}(Y^{\text{DIS}}_{i} = {y}^{\text{DIS}}_{i})} \label{equ:loss-e} \end{equation}
\begin{equation} \mathcal L^{\text{DIS}} = - \frac{1}{N} \sum_{i \in [1, N]} \log{\mathcal{P}_{\theta}(Y^{\text{DIS}}_{i} = y^{\text{DIS}}_{i})} + \log{\mathcal{P}_{\theta}(Y^{\text{DIS}}_{i} = {\widetilde{y}}^{\text{DIS}}_{i})} \label{equ:loss-dis} \end{equation}
\begin{equation} \mathcal L^{\text{NER}} = - \frac{1}{N} \sum_{i \in [1, N]} \log{\mathcal{P}_{\theta}(Y^{\text{NER}}_{i} = y^{\text{NER}}_{i})} \label{equ:loss-ner} \end{equation}
整体训练目标如上式所示,分为三个部分:
$\mathcal L^{\text{E}} $只更新 mBERT 参数,目标是让判别器无法正确区分语种;$\mathcal L^{\text{DIS}} $只更新判别器 FFN 参数,目标是让判别器正确区分语种;$\mathcal L^{\text{NER}} $不更新 embedding 和底下三层 Transformer 参数,目标是让判别器正确识别源语言实体;
完成上述工作之后,我们就可以获得一个在源语言上 Fine-tune 好的 NER 模型和一个语言判别器(共享一个 mBERT)。 此时拿 mBERT-TLADV 去做上述语料来源任务,这个时候它之中的 Language-specific 的特征就会明显减少。
这个时候如果我们拿 mBERT-TLADV 去做类似 UniTrans 的 Distillation 学习,其实已经是一篇工作了。 但是我们继续想,学习得到的 NER 模型和判别器还有什么用处。
对抗学习的目的是模型判断不出来语料的来源,那么对于判别器学的比较好的数据(这里应该是输出概率接近 0.5 左右的, 式$(\ref{equ:l-score})$),所拥有的 Language-independent 信息相对含量(相对于学习得到的 NER 模型而言)就会偏高。
那么我们用这部分来做 Distillation 的话,跨语言学习泛化性应该更好。
这就是模型架构图中的图(b)和图(c)部分。
当我们拿到这部分语料子集$\mathbb{D}_{\text{subset}} = \{x^{\text T}_{\text{subset}}, \boldsymbol{\hat{y}}^{\text{T-NER}}_{\text{subset}}\}$之后,利用源语言上 Fine-tune 得到的 NER 模型标注上对应的 soft label,便构造好相对应的数据。
\begin{equation} \ell_{\text{score}}(\boldsymbol{x}^{\text{T}}) = 1- \left\|\mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{DIS}}, \boldsymbol{x}^{\text{T}}) - 0.5\right\| \label{equ:l-score} \end{equation}
知识蒸馏部分即使用在源语言上 Fine-tune 之后的 NER 模型作为 Teacher 模型$\boldsymbol{h}$,在目标语言伪样本子集上学习一个目标语言 Student 模型$\boldsymbol{h}^{\text{T}}_{\text{stu}}$。
其损失函数为式$(\ref{equ:loss-each})$。
\begin{equation} \mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{T-NER}}) = \text{softmax}(\boldsymbol{W}^{\text{T-NER}}\boldsymbol{h}^{\text T}_{\text{stu}} + \boldsymbol{b}^{\text{T-NER}}) \label{equ:p_stu} \end{equation}
\begin{equation} \mathcal L^{\text{KD}} = \frac{1}{N} \sum_{i \in [1, N]} (\mathcal{P}_{\theta}({\boldsymbol{Y}}^{\text{T-NER}}) - \boldsymbol{\hat{y}}^{\text{T-NER}}_{\text{subset}}) ^ 2 \\ \label{equ:loss-each} \end{equation}
Experiments
在 CoNLL 语料上,对英语[en], 西班牙语[es], 荷兰语[nl]和德语[de]四种语言进行测试。
其中这些数据集的 label 都是相同的四种 PER, LOC, ORG, MISC。
除英语为有标注数据,其他语言均为未标注语料。
选用 mBERT-base 作为 backbone,在训练过程中,freeze embedding layer 和底下三层 Transformer 参数。
超参数$\mathbb{D}_{\text{subset}}$子集的筛选阈值$\rho$设定为 0.8。
(其他训练细节详见 paper)
\begin{array}{c|cccc} \hline & \textbf{de} & \textbf{es} & \textbf{nl} & \textbf{Avg} \\ \hline \text{Beto} & 69.56\% & 74.96\% & 77.57\% & 73.57\% \\ \text{mBERT-ADV} & 71.9\% & 74.3\% & 77.6\% & 74.60\% \\ \text{Meta-Cross} & 73.16\% & 76.75\% & 80.44\% & 76.78\% \\ \text{UniTrans*} & 73.61 \pm 0.39\% & \underline{77.3} \pm 0.78 \% & \underline{81.2} \pm 0.83 \% & \underline{77.37} \pm 0.67 \% \\ \hline \text{mBERT-ft} & 72.59 \pm 0.31 \% & 75.12 \pm 0.83 \% & 80.34 \pm 0.27 \% & 76.02 \pm 0.47 \% \\ \text{mBERT-TLADV} & \underline{73.89} \pm 0.56 \%& 76.92 \pm 0.62 \% & 80.62 \pm 0.56 \% & 77.14 \pm 0.58 \%\\ \textbf{AdvPicker} & \textbf{75.01} \pm 0.50 \% & \textbf{79.00} \pm 0.21 \% & \textbf{82.90} \pm 0.44 \% & \textbf{78.97} \pm 0.38 \%\\ \hline \end{array}
上表展示了部分 Baselines 和一些对比实验结果。 考虑到 UniTrans 中使用了外部翻译模型数据,为了公平比较,此处比较的是 UniTrans 出去翻译信息的结果。 表中下划线部分为对应语言第二好的结果。 可以看出 AdvPicker 在只使用源语言标注数据和目标语言无标注数据的情况下,超过了目前存在的所有方法。 和之前 SOTA,UniTrans*对比分别在德语上超过了 1.41%,在荷兰语上超过了 1.71%。 即使是和使用了外部翻译数据的 UniTrans,AdvPicker 也是可比较的,在平均 F1 中仅差异 0.04。 相对于 mBERT-ft 和 mBERT-TLADV 在 F1 值上分别提升了 2.95%和 1.83%。
虽然上述结果可以说明 AdvPicker 在 Cross-lingual NER 任务上可以取得很不错的效果,但是我们还是想深入探究这样的操作到底改变了什么。
首先我们对对抗判别器,筛选得到的目标语言 Train Set 子集进行分析,首先看这些 Soft label 的质量高不高,即分别测试$\mathbb{D}_{\text{subset}}$和$\mathbb{D}\setminus \mathbb{D}_{\text{subset}}$的准确率。
\begin{array}{c|cccc} \hline & \textbf{de} & \textbf{es} & \textbf{nl} & \textbf{Avg} \\ \hline \mathbb{D}_{\text{subset}} & 77.87\% & 76.45\% & 84.33\% & 79.55\% \\ \mathbb{D}\setminus \mathbb{D}_{\text{subset}} & 63.83\% & 69.23\% & 66.97\% & 66.68\% \\ \Delta & 14.04\% & 7.22\% & 17.36\% & 12.87\% \\ \hline \end{array}
可以看出判别器筛选出来的 data 本身具有更好的 Soft label 质量。 这样也进一步提升之后的 Distillation 学习效果。 那么这样的性质是否保留到 AdvPicker 上呢,因为我们知道 Knowledge Distillation 其实也有一定筛选数据质量的能力。 相应的过程同时作用在目标语言的 Test Set 上。
\begin{array}{c|cccccc} \hline & \mathbb{D}^{\text{de}}_{\text{subset}} & \mathbb{D}^{\text{de}}\setminus \mathbb{D}^{\text{de}}_{\text{subset}} & \mathbb{D}^{\text{es}}_{\text{subset}} & \mathbb{D}^{\text{es}}\setminus \mathbb{D}^{\text{es}}_{\text{subset}} & \mathbb{D}^{\text{nl}}_{\text{subset}} & \mathbb{D}^{\text{nl}}\setminus \mathbb{D}^{\text{nl}}_{\text{subset}} \\ \hline \text{mBERT-ft} & 73.65 \% & 70.66 \% & 77.29 \% & 70.39 \% & 81.67 \% & 69.89 \% \\ \text{mBERT-TLADV} & 74.05 \% & 72.49 \% & 78.04 \% & 73.86 \% & 81.83 \% & 77.89 \% \\ \text{UniTrans*} & 74.48\% & 71.71\% & 77.29\% & 73.18\% & 83.15\% & 70.39\% \\ \textbf{AdvPicker} & 75.11\% & 73.76\% & 79.19\% & 75.68 \% & 84.19\% & 79.15 \% \\ \hline \end{array}
可以看到虽然 AdvPicker 没有见过训练集中$\ell_{\text{score}}(\boldsymbol{x}^{\text{T}})$比较小的数据,但是在测试集的 Other 子集上仍然超过所有的 Baselines。
其次,对比 UniTrans*和 mBERT-TLADV, Knowledge Distallation 可以进一步提升模型在两个子集上的效果,而且 mBERT-TLADV 通过对抗学习学习得到的 Language-independent 使得模型具有更好的泛化性,在 Other 子集上甚至超过 UniTrans*。
此外,还进行了一些消融实验,进一步证明了各个组件的作用。
\begin{array}{c|cccc} \hline & \textbf{de} & \textbf{es} & \textbf{nl} & \textbf{Avg} \\ \hline \text{AdvPicker} & 75.02 & 79.00 & 82.90 & 78.97 \\ \hline \text{mBERT-ft} & 72.59 (-2.43) & 75.12 (-3.88) & 80.34 (-2.56) & 76.02 (-2.95) \\ \text{mBERT-TLADV} & 73.89 (-1.13) & 76.92 (-2.08) & 80.62 (-2.28) & 77.14 (-1.83) \\ \text{AdvPicker w/o KD} & 73.98 (-1.04) & 77.91 (-1.09) & 80.55 (-2.35) & 77.48 (-1.49) \\ \text{AdvPicker w All-Data} & 74.02 (-1.00) & 78.72 (-0.28) & 80.69 (-2.21) & 77.81 (-1.16) \\ \hline \end{array}
总结和讨论
本文从 Cross-linugal 任务应该扑捉 Language-independent 特征的角度出发,设计了一个评价 Langauge-specific 程度的任务。 并根据此,设计了一种字符粒度的对抗学习策略从而提升模型学习 Language-independent 特征的程度。 并利用对抗判别器划分无标注目标语言子集,继而构建 Soft label 和 Knowledge Distillation 进一步提升模型在目标语言上的效果。 实验证明在无外部数据的前提下,AdvPicker 在三个语言上均超过之前的 SOTA。 并设计实验对判别器产生效果的原因进行了具体分析。
实际上,这种方式可以看做为一种带权值批处理版本的 Self-training 或者 Co-training。 但事实上,这种 Subset Data 的选择是与 NER 模型和判别器息息相关的,它选择出来的 Data 是在当前 NER 模型下相对 Language-independent。