从ECMo、Bert看Word Embedding
ECMo = embeddings from a conversation model
ECMo 是一种基于多轮对话上下文关系的 Embedding 模型 发表于Improving Matching Models with Contextualized Word Representations for Multi-turn Response Selection in Retrieval-based Chatbots C. Tao et al. 2018
虽然这篇文章没有发布在各大会议上 只是贴在 Arxiv 上面 但 Motivation 和 Bert 一致 可以看出想法还是好的
然后这篇文章的三作 是上次回来讲XiaoIce的学长 羡慕 🤤
Motivation
自从 word2Vec 发布之后 NLP 任务 就被定义为 两步 一步词向量 一步后续模型
但是 word2Vec 跑的模型是不包含上下文信息 只是单向的
这个时候就想为啥不能像后续模型一样 通过交互把 把句子间的关系也反映出来
当是词级别的 Embedding 很容易造成词向量本身带有歧义
于是这个时候就想能把Pre-Train过程做的像后面一样
实际上如果你跑过 QA 模型的时候 就会发现 Accurate 大头都在 Embedding 过程
比如如果把后面全部去掉 只做一个 Embedding 然后直接 Cosine Similarity 可能只掉 5.6 个点
所以 Embedding 好坏决定了 决定了模型的下限
word2Vec
在讲 ECMo 之前需要复(yu)习一下 word2Vec
我想大部分人对 word2Vec 肯定不陌生 起码会掉 gensim 的包
但不一定会其原理熟悉
word2Vec 思路其实和我们之前用到的大部分模型一致
就是在当前 word 和 下一个 word 之间 找一个映射关系 f
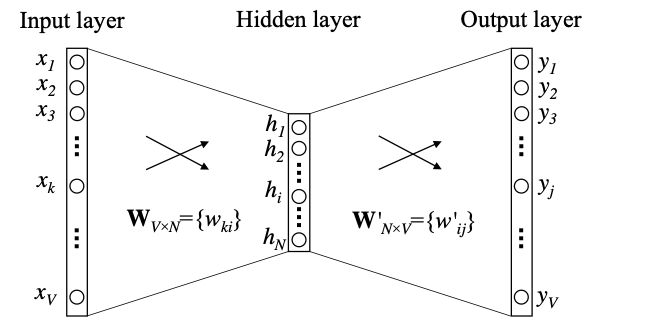
而这个 f 代表了当前 word 的属性 把映射关系 f 的参数拿来 作为当前 word 的词向量
在这里并不关心预测结果 只关心训练完的副产物 模型参数 第一个这么做的还不是 word2vec 而是nlp almost from scratchR Collobert et al.2011
输入 和 输出不一定只有一个词
- 一个输入 多个输出 Skip-gram
- 多个输入 一个输出 Cbow
那么就有一个问题 word2Vec 的输入值怎么确定?
首先肯定不是 Word2Vec 值 那是中间产物
在 genism 中采用的是 random N 维向量 丢进去 然后 慢慢摩擦 摩擦 得到了我们需要的 Embedding 值
当然你可以可以用 one-hot(就是 出现的词 那一维度 置为 1 未出现置为 0)
可以看出初始值是什么 与结果怎么样关系不大 只和收敛 epochs 有关
然后 word2Vec 跑的是Hierarchical log bilinear language model 只不过把回归函数进行简化
把$P(w_n=w|w_1,\cdots,w_{n-1})=\sigma(v_w \cdot \sum\limits_{i=1}^{n-1} C_i v_{w_i} + b_w)$简化为$P(w_n=w|w_1,\cdots,w_{n-1})=\sigma(\frac{1}{n-1} v_w \cdot \sum\limits_{i=1}^{n-1} \tilde{v}_{w_i})$
这样改进 可以大幅度提升运行效率
另外 word2Vec 还引入了 Negative sample
负采样是解决 SoftMax 维数太大 计算效率低的问题 在计算 SoftMax 的时候除了一个正例之外 随机采样几个负样本 只要模型能中这几个样本中训练出正例就行了
\begin{equation}\log\sigma(v^{T}_{w_0}v_{w_I})+\sum\limits_{i=1}^KE_{w_i}[\log\sigma(-v^{T}_{w_i}v_{w_I})]\end{equation}
其中$v'_{w_0}$为正例, $v'_{w_i}$为负例 k 个 $\sigma$为 sigmoid 函数 即极大正例似然 极小负例似然
这样 word2Vec 在运算效率就比之前的一些 Embedding 效果好很多
再加上那个King - man = queen - woman的例子 导致了被广泛应用于 NLP pre-train 过程
然后还有一点就是 word2Vec 的过程 相当于矩阵分解的过程 是一个全局 PPMI(共现)矩阵的分解
我们在做 word2Vec 得到的结果是其实是两个向量 一个是所需要的词向量 word 还有一个本应该输出的记过向量 reply
word2vec 的过程 对于每一个不同的 word 生成一个相对应的 reply 就相当于 把一个矩阵 分解为 word×reply
证明详见Neural word embedding as implicit matrix factorizationLevy et al. NIPS 2014Word embedding revisited: A new representation learning and explicit matrix factorization perspectiveLi Yitan et al. IJCAI 2015
ECMo
明白了 word2Vec 的原理 那么 对于利用模型进行 Word Embedding 的合理性应该就清楚了
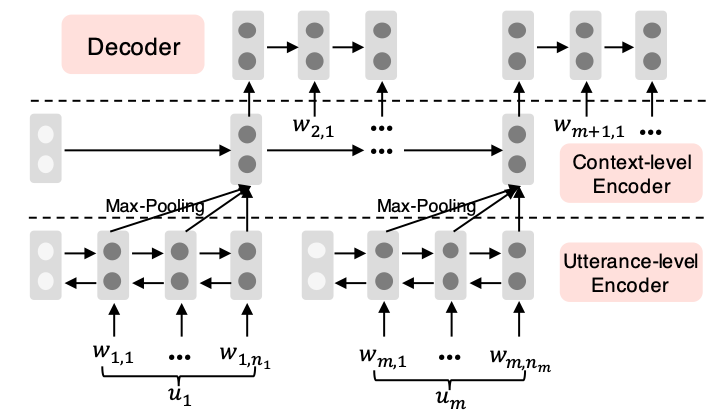
在 ECMo 中利用了一个叫分层编码-解码 hierarchical encoder-decoder (HED)的模型进行训练
首先是一个词语级的处理 经过一层双向 GRU(BiGRUs) 然后对每个词进行最大池化处理 结果作为第二层的输入
第二层是一个上下文级别的处理 经过另外一个 GRU 然后最后一层输出到解码阶段
解码阶段利用一个 RNN 进行反向推测 由前一个词$u_{n+1}$ 推测下一个词$u_{n}$
\begin{equation}p(u_{n+1}|u_1,...,u_n)=p(w_{n+1,1}|h^s_n)\prod\limits_{t=2}^{T_{n+1}}p(w_{n+1,t}|h^s_n,w_{n+1,1},...,w_{n+1,t-1})\end{equation}
其中,
\begin{equation}p(w_{n+1,t}|h^s_n,w_{n+1,1},...,w_{n+1,t-1})=II_{w_{n+1,t}}.\text{softmax}(h^d_t,e_{n+1,t-1})\end{equation}
而$h^d_t=GRU_d(h^d_{t-1},e_{n+1,t-1})$, $II_{w_{n+1,t}}$为 one-hot
而 word Embedding 值 即 ECMo 就是 HED 中的$h_i^s$值
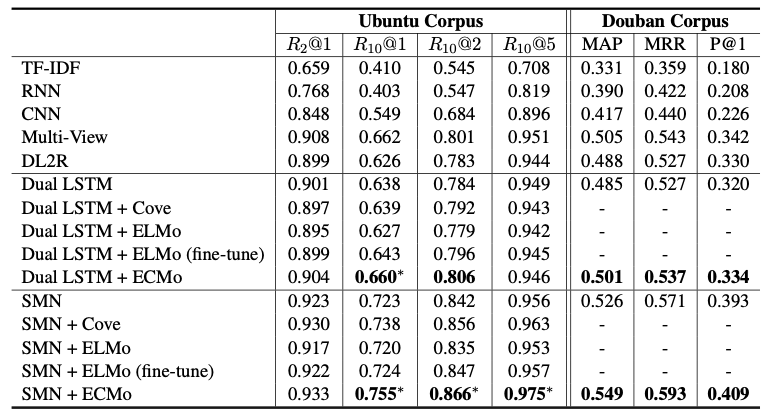
文章中在 Ubuntu 和 Douban 两个 dataset 上面做了测试
其中优化函数选择 Adam 学习率$1e^{-3}$ 所有 GRU 及 RNN 的隐层数为 300 取最大 session 为 10 最大 utterance 为 50
Bert
bert 已然是当今学界的热点
那么为啥 Bert 效果那么好
Bert 相当于在预处理阶段 把 dataset 中 字符级别、词级别、句子级别 甚至句子间所有特征抓取到
这样在处理特定 NLP 任务的时候 只需要对输出向量进行些许处理即可
那么究竟是如何操作的呢
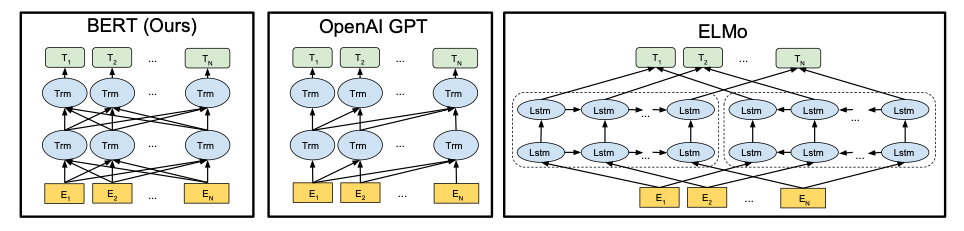
深度双向 Encoding
深度双向 Encoding 在后续模型中早就被广泛采用
但在模型的 Pre-train 阶段很少有做到如此复杂的处理 像 word2vec 仅仅是单向线性
效果已经很好 ELMo 也仅仅是两个方向的 RNN 分别进行操作 然后直接加和
Bert 为了达到这种深层双向 Encoding 的功能 做了一件我们从小都在做的事情 完形填空
把遮住上下文中任意一个单词 通过训练出这个地方应该是什么单词
可以想象的出来 这个复杂度 不是一般的高 很羡慕有 TPU 的了
但这样就会在 Encoding 的时候也会把标记也 Encoding 于是作者想了一个办法
- 80% 概率 用
[mask]替换单词 - 10% 概率 用随机采样的单词替换
- 10% 概率不替换
这样让模型学习到 这个地方有一个空
然后用 Transformer 来做 encoding 首先 TPU 对 transform 支持更好
其次 transform 相较于 RNN 系 有更好的并行性 和 长时间记忆性
为了保证位置信息 在 bert 中 训练一个 position Embedding 在论文中直接用了一个 one-hot 作为输入
然后 慢慢训练 (我错了 有 TPU 的是快快训练)
于是加上这些 就变成了 24 层 multi-head attention block 每个 block 16 个抽头 1024 个隐层 瑟瑟发抖 😨
句粒度
然后上面只获得了词级别的特征 对于句粒度的任务效果不会太好
在这里 Bert 很疯狂的把 word2vec 中负采样 拿到这边
只不过变成了句子粒度的
同样是跑 transform 得到一个segment Embedding
然后把它和前面的词级别的token embedding + 位置信息position embedding直接加和在一起
然后 对于任何 NLP 任务只需要在这之后 做一些简单的操作就行了 比如说 MLP 什么的
跑过 Bert 除了确实比较慢之外 全量数据可能要 200 多天 但效果真的好 1%数据在测试集上的准确率就达到 0.567 还用的是 base 版
不得不佩服 Google Brain 就是没钱 qiong
可以看到随着 NLP 研究的推进 随着硬件 软件 的成熟化发展
Embedding 从最开始的 One-hot 到从 NN 中间参数获取的 word2Vec 再到双向 Encoding 的 ELMo 最后到全能的 Bert
对预处理越来越重视 也认识到预处理过程 对整个模型的重要性
当然更重要的是 对自己没钱 没本事的认识 呜呜呜
Reference
- Improving Matching Models with Contextualized Word Representations for Multi-turn Response Selection in Retrieval-based Chatbots
C. Tao et al. 2018 - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob et al. 2018 - word2vec Parameter Learning Explained
Xin Rong 2014 - word2vec 相比之前的 Word Embedding 方法好在什么地方?
- 词向量,LDA,word2vec 三者的关系是什么?
- NLP 的游戏规则从此改写?从 word2vec, ELMo 到 BERT