🥷 个人博客学术化及接口权限改造
说实话又一年没写博客了,不过终于毕业了,也许以后可以有更多的时间写写博客(tao。
趁着还没入职的间隙,做了一些博客改造的开发工作,其中运维:JavaScript:Python:Java 工作量占比大概 $5:3:2:1$,总共间断的开发了两周多。
🤹 Motivations
想必各位 NLPer 看苏神博客的时候一定被其丰富的知识量和阅读体验极佳的公式震撼过。
出于这点考虑,本期的学术化改造的一个目的就是提供良好的公式编译能力,增强对 $\LaTeX$ 的支持。
其二,作为学术类博客,需要提升评论及引用能力,提供相应的 $Bib\TeX$。
其三,更清晰的 Tag 维护策略,Tag 之间存在层级关系。
除此之外,放开静态文件爬取限制,收紧 API 接口权限,实现动态管理,(其实这个一直想做的,只是没想到做起来那么花时间。
🕹 Developing
前三条,都是 JavaScript 的工作。 由于历史原因,本博客用的还是 Vuepress@0.16,看了一下 v1 版本 lib 代码改动不大,等 v2 发 beta 版了有空再改吧(能用就将就用着。
MathJax
有别于苏神使用 php 开发的博客,Vuepress 是一个基于 markdown-it 的框架。
而 Markdown 天生就和$\LaTeX$不搭,比如说_在 Markdown 中表示 $x_i + y_i$ 会被编译为x<em>i + y</em>i。
而我们的目标是支持 MathJax 而不是 katex 这种阉割版本。
参考 Yihui Xie 在The Best Way to Support LaTeX Math in Markdown with MathJax提供的思路,
利用<code>标签提供一个不会被 markdown-it 侵入的环境,再对 markdown-it 编译好的 body 做 code 标签解除,以便 MathJax 的 JavaScript 代码能够渲染相应公式区域。
replaceLatexCode(){
var i, text, code, codes = document.getElementsByTagName('code');
for (i = 0; i < codes.length;) {
code = codes[i];
if (code.parentNode.tagName !== 'PRE' && code.childElementCount === 0) {
text = code.textContent;
if (/^\$[^$]/.test(text) && /[^$]\$$/.test(text)) {
text = text.replace(/^\$/, '\\(').replace(/\$$/, '\\)');
code.textContent = text;
}
if (/^\\\((.|\s)+\\\)$/.test(text) || /^\\\[(.|\s)+\\\]$/.test(text) ||
/^\$(.|\s)+\$$/.test(text) ||
/^\\begin\{([^}]+)\}(.|\s)+\\end\{[^}]+\}$/.test(text)) {
code.outerHTML = code.innerHTML; // remove <code></code>
continue;
}
}
i++;
}
},
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
不过需要注意的是 Vuepress 中联系访问页面是 SPA,进入下一页之后需要重新做上述操作。
getMathJax() {
const script1 = document.createElement('script');
script1.src = 'https://xxxx/MathJax-2.7.4/AMS-setcounter.js';
script1.type = 'text/javascript';
script1.id = "ams-counter";
setTimeout(() => document.body.appendChild(script1), 500);
const script2 = document.createElement('script');
script2.type = 'text/javascript';
script2.src = 'https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.4/MathJax.js?config=TeX-AMS-MML_HTMLorMML';
script2.id = "tex-ams";
setTimeout(() => document.body.appendChild(script2), 700);
setTimeout(() => document.getElementById("ams-counter").remove(), 2000);
setTimeout(() => document.getElementById("tex-ams").remove(), 2000);
},
2
3
4
5
6
7
8
9
10
11
12
13
14
(其中AMS-setcounter.js是借鉴苏神的配置。
然后公式的颜色感觉还是蓝色最合适,其他看的都容易困(主要是太菜了
使用的时候一定要带上在反引号中带上 dollar 符或者\begin{}\end{} (单行公式在博客里阅读体验++
$bib\TeX$ 和 Utterence
(可能是毕业论文写傻了,自然而然的想到应该给博客加一个$bib\TeX$的功能。
这点技术难度几乎没有,只不过为了更好的支持中文人名(Last Name, First Name)的形式,将原先 config.js 中的 author 拓展成 authorLastName 和 authorFirstName。
需要注意的是同样由于 SPA 也需要对反复渲染,(我这边实现的比较丑陋,没有用成 vue 中的 watch。
此外对于评论模块做了迁移,之前一直使用的是 Gitalk,也在利用 Gitalk 给 Vuepress 搭建的 blog 增加评论功能介绍了 Vuepress 中的实现。
它确实样式美观,GitHub Issue 的方式既能控制评论权限也能方便数据迁移。 但是它的缺点十分明显:
- 暴露 Github Token;
- 必须每篇 blog 都建立一个 Issue 即使是没有人评论的;
第二点是我不太能忍的,主要是有一直看 Issue 的习惯。大家也知道,我以前一直是用一个 Issue 管理所有博客的评论,这对之前评论的人也是一种打扰。 我设想中应该是主动 Push 型的,有人评论再去建 Issue,本来已经想自己实现了,结果发现有一个叫 Utterence 的插件完美的实现了我的需求。
借助 Bot 的形式也能规避 GitHub Token 的暴露。
不过它使用 iframe 的形式,让自定义 style 变成了不可能,所幸 PC 端和移动端的样式也还能接受。
同样因为 SPA 需要反复渲染。
Multi-level Tags
考虑到 Tags 这个东西实际上是类似于 Key Word 的东西,像 ACM 系列的会议/期刊都会按多级的方式显示以便不同兴趣的学者能快速定位到相应的文章。
之前实现的是单一级的 Tags,导致 Tags 并不能展示文章的分类信息。
于是实现了一个多级(考虑到实际使用需求最大级数定为 3 级),并支持叶子层多 Tags 的方式,例如NLP/LM/(KnowledgeInject#KnowledgeBase)就表示了NLP/LM/KnowledgeInject和NLP/LM/KnowledgeBase两条三级路径。
实际上是一个多叉树结构,需要对树做建树和深度遍历(Tags 页线性展示),大概是一个 LeetCode Easy 的题。
export function dfsTagGraph(root, tagG, done) {
const queue = [];
const res = [];
queue.push([root, 1]);
while (queue.length) {
var top = queue.pop();
if (done.has(top[0])) {
continue;
}
done.add(top[0]);
res.push(top);
const children = tagG[top[0]] || [];
children.forEach(c => {
if (!done.has(c)) {
queue.push([c, top[1] + 1]);
}
})
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
同样需要注意的是需要反复渲染。
权限管理
(事先说明,这个策略还是很简陋的,请各位安全大佬手下留情 🙊
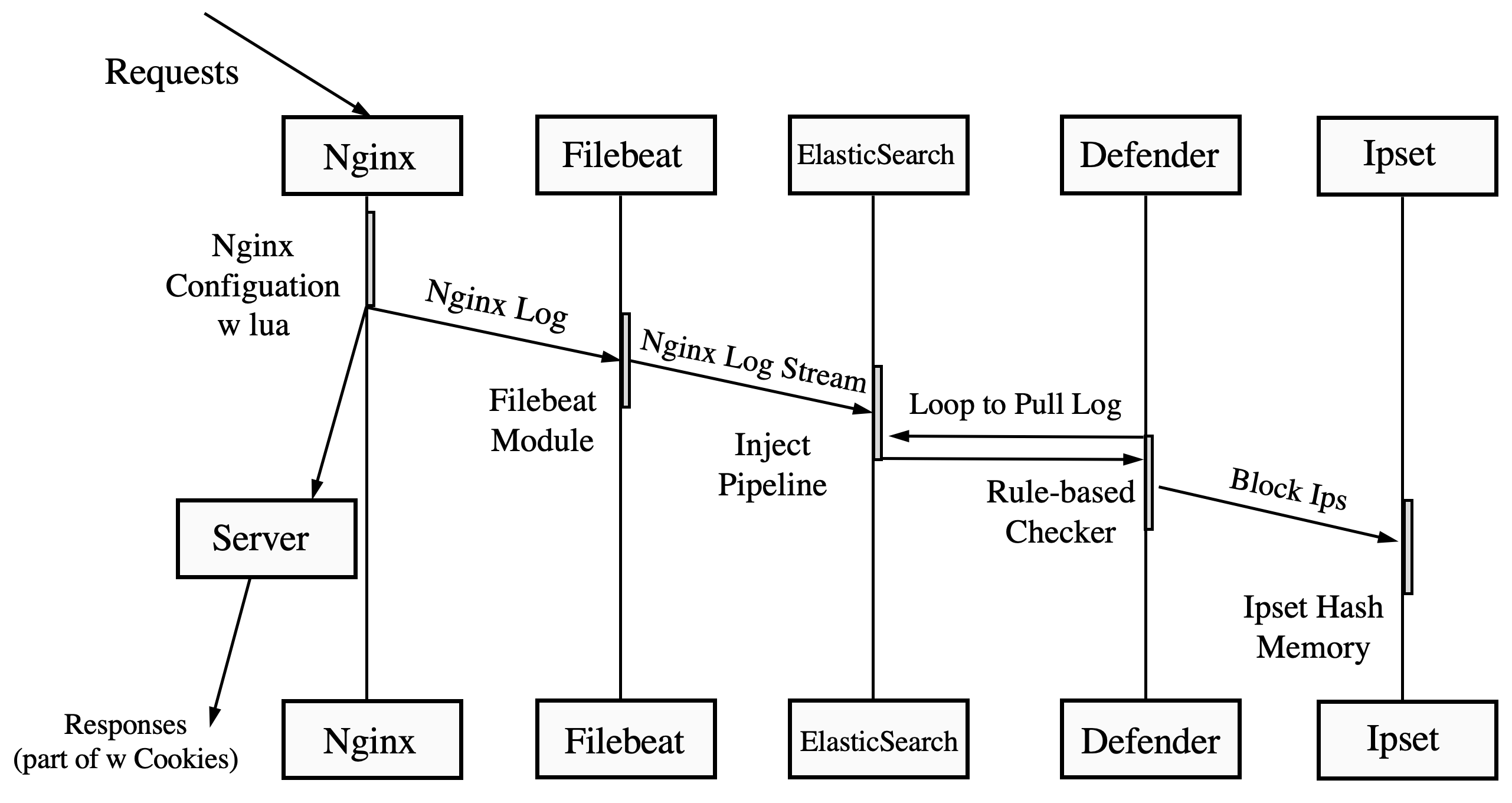
下面来到最重头的权限管理,这其实是我一直想做的,之前从Nginx 配置和Nginx 日志分析两方面做了限制。
但是这个限制是天粒度的,定时跑脚本也行,但是对于时间边界整体是不敏感的。
究其原因,是因为 Log 是以文件形式存放,失去了流属性和时间属性。
ELK
调研之后,使用 ElasticSearch + Kibana + Filebeat 方案。 Filebeat 监听 file 当 file 开始更新的时候会分配一个 registrar 去执行相应 pipeline。
Filebeat 是极其轻量的,可以定义一些 js 脚本处理格式等问题,自身也提供 Module 以供进行解析常见软件 log。 推荐这种方式,以 Nginx Access Log 为例,还会对 Ip 进行 geo 分析,对 User-Agent 也会进行解析,这节省了我们大量分析工作。 (当然 Nginx 自身也提供 Geo 不过需要你安装特定的插件。
由于 Filebeat 是轻量的,这些 machine_learning Jobs 都是推到 ElasticSearch 上由 Java 来执行的。 所以如果你想利用 Module 由 Filebeat 传到 Redis 的话,那得自己做 geo 和 UA 解析。
整体架构如下图所示,
大部分时间花在搭建和配置上了,即使是用 docker。贴一下搭建过程中踩的坑
- ES 和 Kibana 默认只开放本地操作权限,如要 remote 操作,需要设定 host:"0.0.0.0";
- 我是用一台机子放 ES + Kibana,然后两台机子 Filebeat 到 ES 机子上。通过 Nginx 转发 ES 和 Kibana 请求,大部分均正常,只有在 Kibana 下少部分 POST 会返回 413,这就导致 FileBeat 连接带不同主机(不同内网域)的 Kibana 时候必须开个端口用域名连接。(此处控制变量判断问题源)
- Kibana 和 ES,Filebeat 的密码相关设定不要明文写在文件中,但是不同的 keystore 接口不同,Kibana 的 KEY 直接是 config 的 key(也只能是)
ELK 之后还可以做很多应用,比如说数据上报实时展示,通过 Kibana 的 timelion 进行绘图,(这又是另外一个坑了
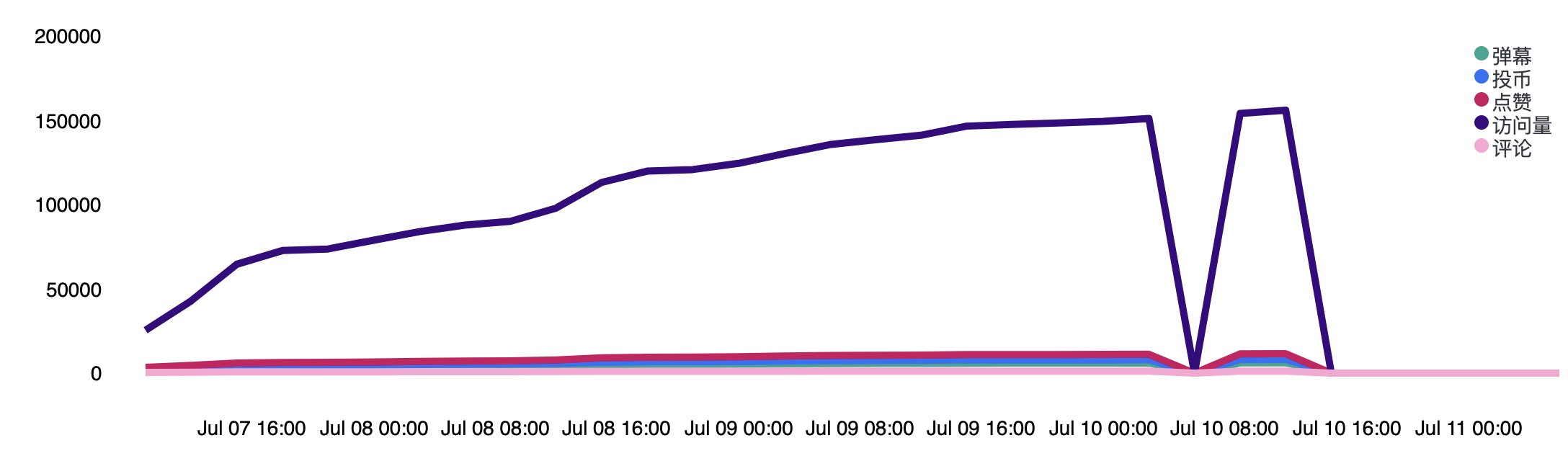
除了 ES 提供的数据,还需要进一步扩充数据源。
- 明确 IP 对应服务器用途,利用 Ip2Proxy 查询 geo 解析得到的 asn 所对应的临近 IP 端用途,如果 IP 端较近则认为用途一致;
- 收集所有 Header 信息,这个需要配置 Nginx 启动 Lua,参考StackOverFlow.
- 相对应的 Filebeat Inject 也需要做对应的修改
nginx.conf 配置如下
log_format myformat escape=none '$remote_addr $host $hostname $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" "$http_cookie" @$request_headers@';
access_log logs/access.log myformat;
set_by_lua_block $request_headers{
local h = ngx.req.get_headers()
local request_headers_all = ""
for k, v in pairs(h) do
local rowtext = ""
rowtext = string.format("[%s:%s] ", k, v)
request_headers_all = request_headers_all .. rowtext
end
return request_headers_all
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
相对应的 Filebeat 的 Inject Pipeline 配置
(%{NGINX_HOST} )?\"?(?:%{NGINX_ADDRESS_LIST:nginx.access.remote_ip_list}|%{NOTSPACE:source.address}) (-|%{DATA:url.host}) (-|%{DATA:user.name}) \\[%{HTTPDATE:nginx.access.time}\\] \"%{DATA:nginx.access.info}\" %{NUMBER:http.response.status_code:long} %{NUMBER:http.response.body.bytes:long} \"(-|%{DATA:http.request.referrer})\" \"(-|%{DATA:user_agent.original})\" \"(-|%{DATA:header.x_forward})\" \"(-|%{DATA:header.cookie})\" @(-|%{DATA:header.original})@
当获得数据之后,定时获取区间数据,进行策略分析(需要控制度)和 Ipset 封禁。
此外还在服务端增设 Cookies 用以辅助权限管理。
总结
本文针对本博客从 MathJax、Tags、评论、$bib\TeX$四方面做学术化改造,并利用 ElasticSearch + Kibana + Filebeat 提出一种权限管理策略。
水平有限,欢迎讨论。