浅谈多轮检索式对话最近的两篇SOTA-『MRFN』&『IMN』
新年第一天更博 显得很有
仪式感(破音~)(虽然已经断更一个月了 捂脸) 祝各位NLPer, 各位dalao在新的一年里灵感爆棚 投的 offer 全中 万肆如意 新年玉快
新年第一天 日常网上冲浪 竟然发现MRFN终于被放出来了 啊 啊 啊~~
这篇论文我从去年十月一直等到现在
在这期间中不乏有 Bert 这种神器爆出来
但并没有打消我对这篇 SOTA 的期待
IMN 则是上个月中科院几位博士在 arXiv 在线发表的一篇论文 主要是被数据吓坏了 有、厉害 🙇
粗粗看 可能觉得这两篇文章没什么关系 一个是多粒度 fusion 一个是类似于 Bert 的深层次网络处理
但仔细思考 IMN dot 之后的结构与MRFN的 FLS 有异曲同工的作用 不负责的猜测 FLS 的设计思路会成为今后一段时间 follow 的点
PS: 以上两篇 paper 都承诺开源 code (虽然 repository 里面都没有 code😂) 之后会跟一下 code 看一下具体效果
概括一下 MRFN
- 在原来 SMN DAM 两粒度 基础上提出三粒度 6 种表示
- 提出多表示匹配-合并(Matching-Aggregation)的三种策略
- 使用大量实验验证各个表示的作用,验证 context 轮次、平均对话长度变化时各个表示的作用情况
- 提出的多表示匹配-合并策略可推广到其他模型 并在 SMN 中进行试验
- 比 DAM 快 1.9x 的训练速度
IMN
- EMbedding 层加入 character-EMbedding 解决 OOV
- EMbedding 层后接类似 ELMo 思路的 BiLSTM(paper 中 这个结构最 work)
- dot 之后做两个粒度的分析
MRFN
MRFN = Multi-Representation Fusion Network
MRFN是严睿老师组里陶重阳博士,小冰组徐粲学长,武威 dalao 去年的工作 论文发表在WSDM2019上
全文看下来 包括 Motivation,实验设计都给我一种很舒服的感觉 感觉一切都顺理成章 一气呵成
事实上 去年十月底 在EMNLP2018的 tutorial 上严老师和武威 dalao 就已经把MRFN的结果秀出来了
之后徐学长回来分享的时候也提到这篇论文 但论文一直没放出来
Motivation
这篇文章的 Motivation 是建立在最近几年多轮检索式对话基于的面向交互的思想
回想一下从 Multi-view 引入交互,到 SMN 完全基于交互,再到 DAM 多层交互
交互的粒度越多越 work 已经是大家的共识了
但如何更好的设计各个粒度之间的层次关系 减少不必要的性能浪费
作者提出把粒度划分为word, short-term, long-term三个粒度 6 种表示
Wordcharacter EMbedding: 利用字符级别的 CNN(n-gram)解决 typos/OOV 的问题Word2Vec: 这里很简单的用了 word2Vec 很显然用 ELMo Bert 等会有更好的效果 当然效率上面就不太划算
ContextualSequential: 借用GRU的结构实现句子中间子串信息的获取- RNN 能保留短距离词之间的关系 相对于
sub-sequential
- RNN 能保留短距离词之间的关系 相对于
Local: 利用CNN获取 N-gram 的信息- CNN 中卷积和池化 相对于获取中心词周围
N-gram的信息
- CNN 中卷积和池化 相对于获取中心词周围
Attention-basedself-Attentioncross-Attention
Model
但怎么把这些粒度有效的融合在一起
回想一下 SMN 在 CNN 之后才将word和short-term两个粒度的信息融合在一起
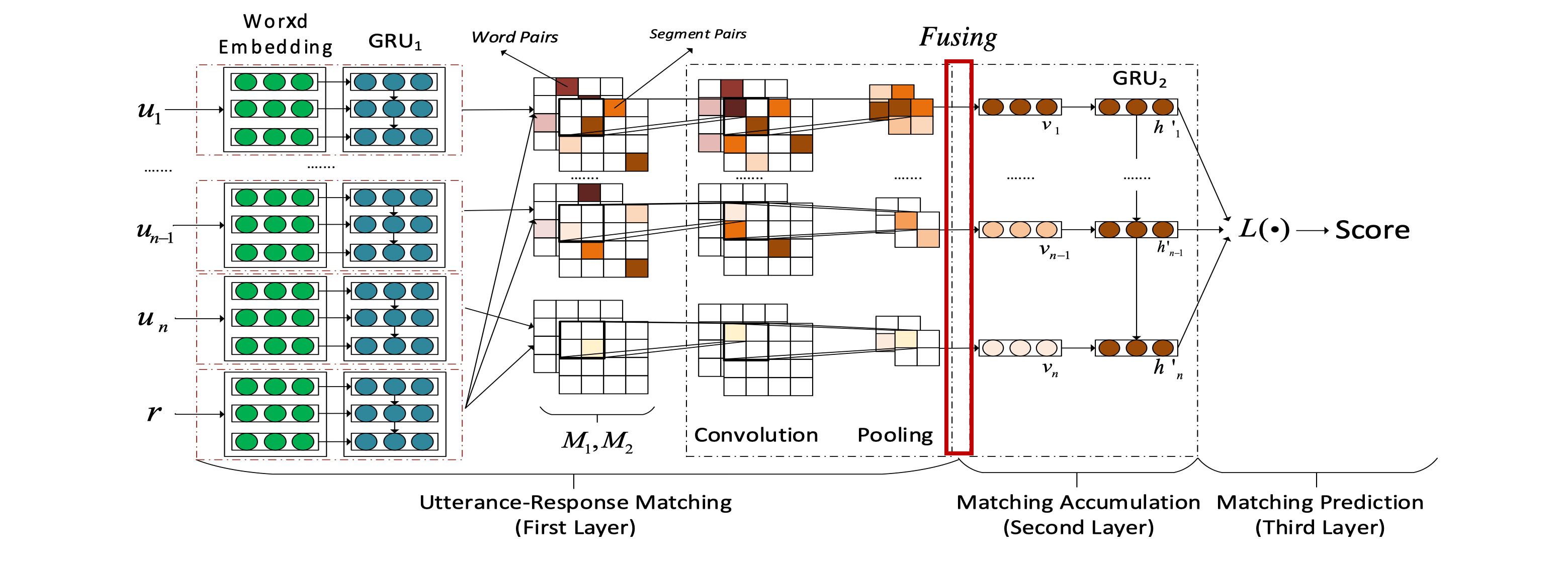
很自然的想到 如果在之前/之后做 fuse 效果会怎么样?
这个思路 就很像NIPS14 年那篇讨论是应该先 dot 还是应该先做 CNN 的 paper
作者就提出前中后三种fusion策略
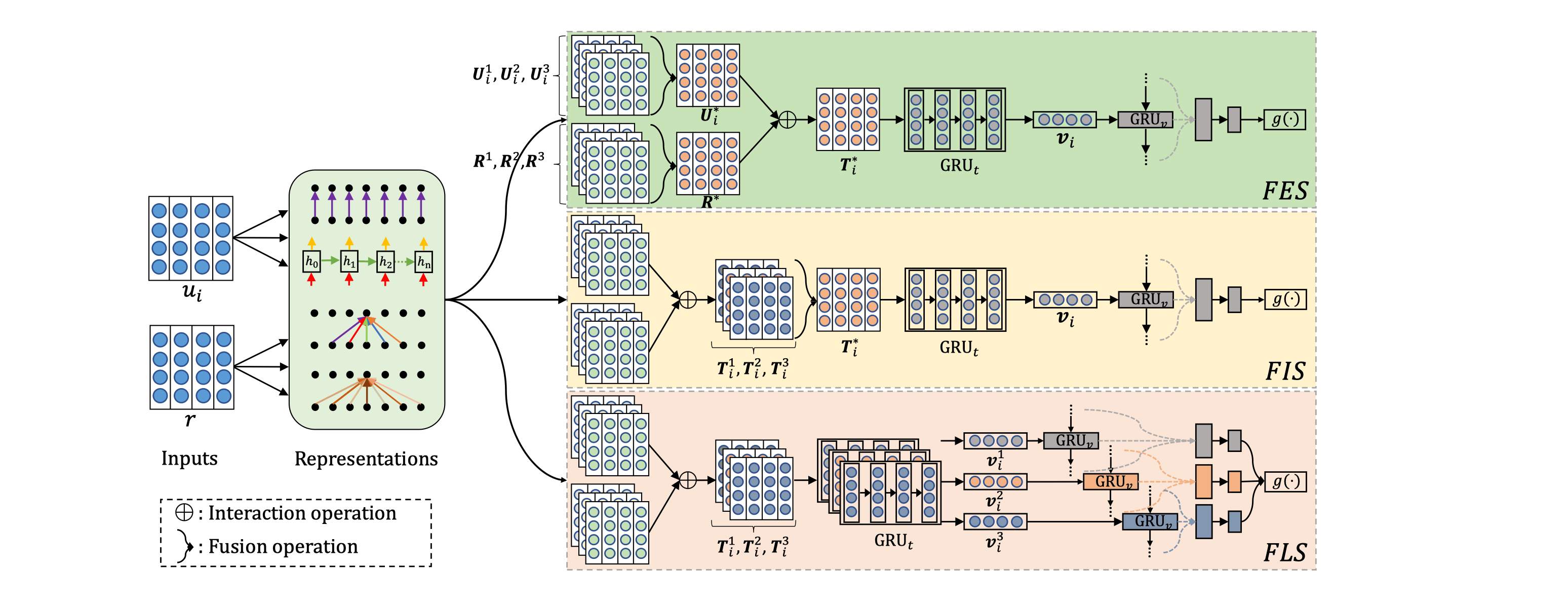
其中左侧是之前设计的 6 钟表示
U->U*的过程是简单的把多个矩阵拼接成一个矩阵
\begin{equation}U^*_i \in R^{d^* \times n_i}(d^*=\sum d_k)\end{equation}
而fusion则是利用类似CNN的公式
\begin{equation}t_{i,j}=f(\hat{e_{i,j}},\bar{e_{i,j}})=ReLU(W_p[(\hat{e_{i,j}}-\bar{e_{i,j}}) \odot \hat{e_{i,j}}-\bar{e_{i,j}});\hat{e_{i,j}} \odot \bar{e_{i,j}}]+b_p)\end{equation}
其中
\begin{equation}w_{j,k}^i=V_a^T tanh(W_a[\hat{e_{i,j}\oplus \hat{e_{r,k}}]+b_a})\end{equation}\begin{equation}\alpha_{j,k}^i=\frac{exp(\omega_{j,k}^i)}{\sum(exp(\omega_{j,k}^i))}\end{equation}\begin{equation}\bar{e_{i,j}}=\sum{\alpha_{j,k}^i}\hat{e_{r,k}}\end{equation}$\odot$ 就是Hadamard dot (或者叫element-wise multiplication)
之后就跟上GRU和MLR得到相应的 score 值
Experiment
本文做了大量的实验 羡慕 MSRA 有用不完的机器 呜呜呜
- 先是对比之前存在的一些模型
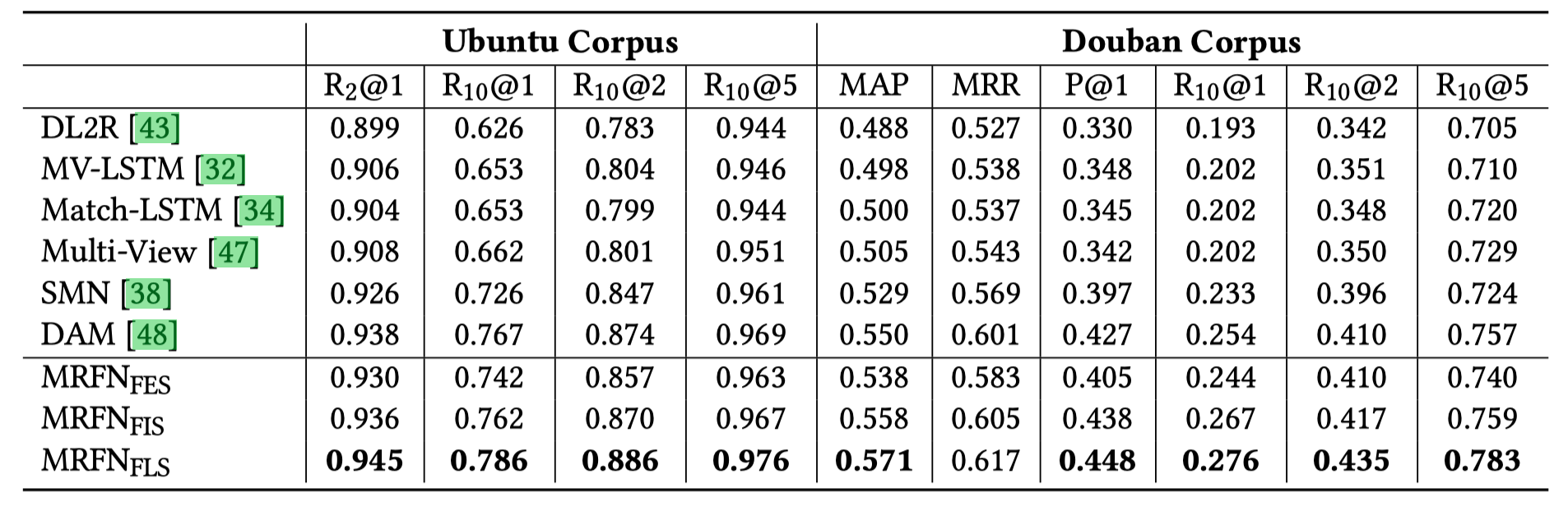
可以看出FLS效果比DAM提升比较显著 即使是 FIS在 Dubbo 数据集上也比 DAM 略微好一点
- 然后还做了把模型结构中各个部分去掉之后的一些结果
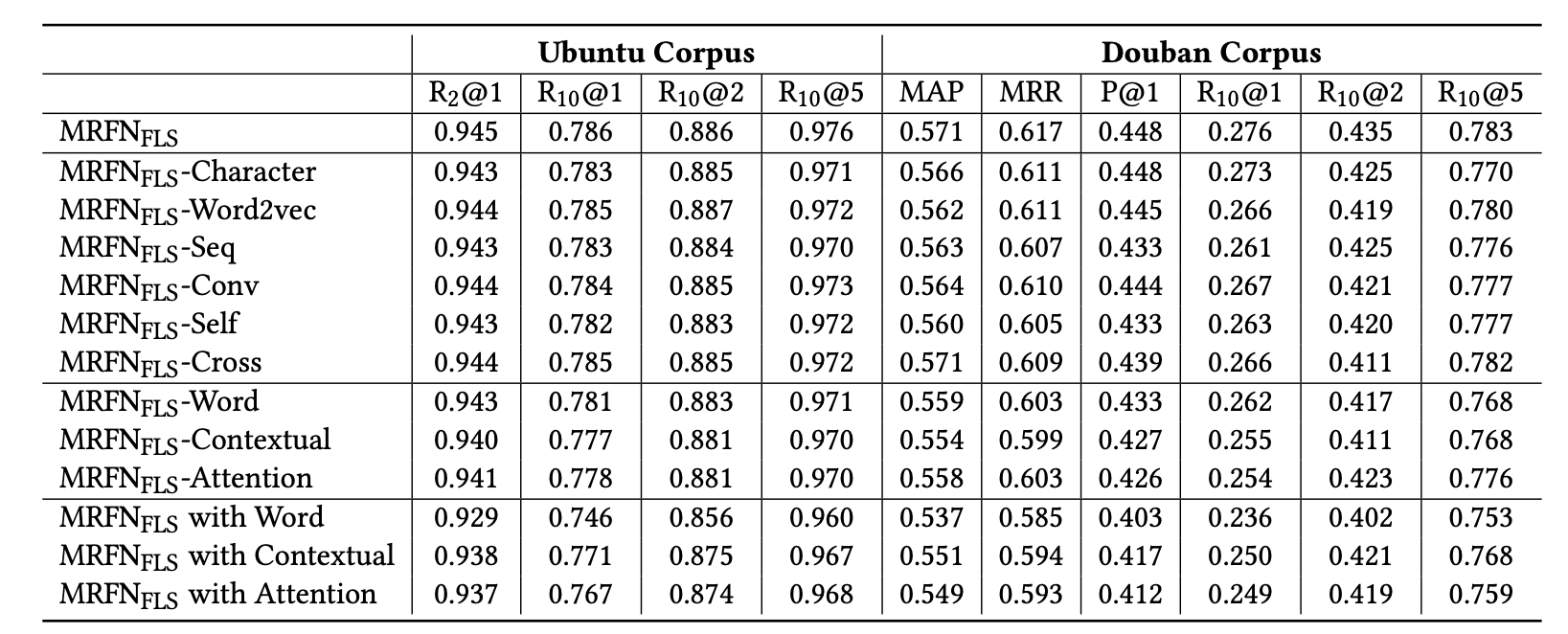
可以看出Contextual两个部分效果略有重叠导致了去除其一掉点不会太多 总的来说Contextual在模型中提点最大
- 还做了模型拓展性方面的实验 把
fusion三策略移到SMN也得到了不错的结果

- 最后还探究了多轮对话 Context 轮次 对话长度变化时各个表示的作用占比情况
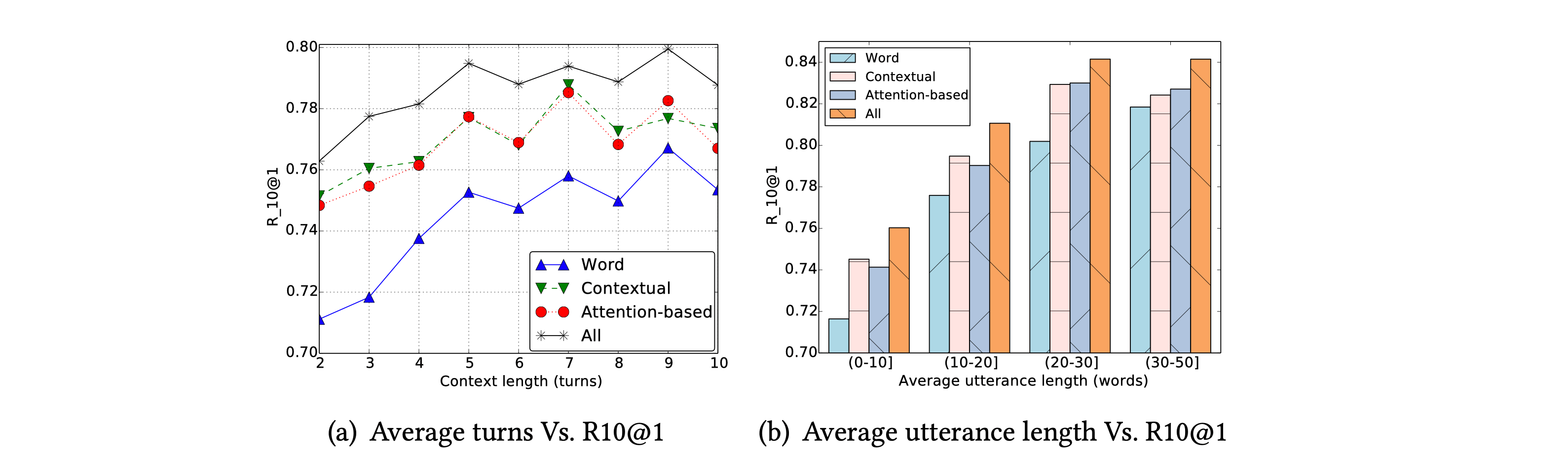
全篇看下来 对于一个做系统出身的出身来看 十分舒服 可以说是比较Science 得到的结果也比较significantly
IMN
IMN = Interactive Matching Network
相对而言 IMN 论文写得有点随意 取名字也有、😶(不是喷 吐槽一下)
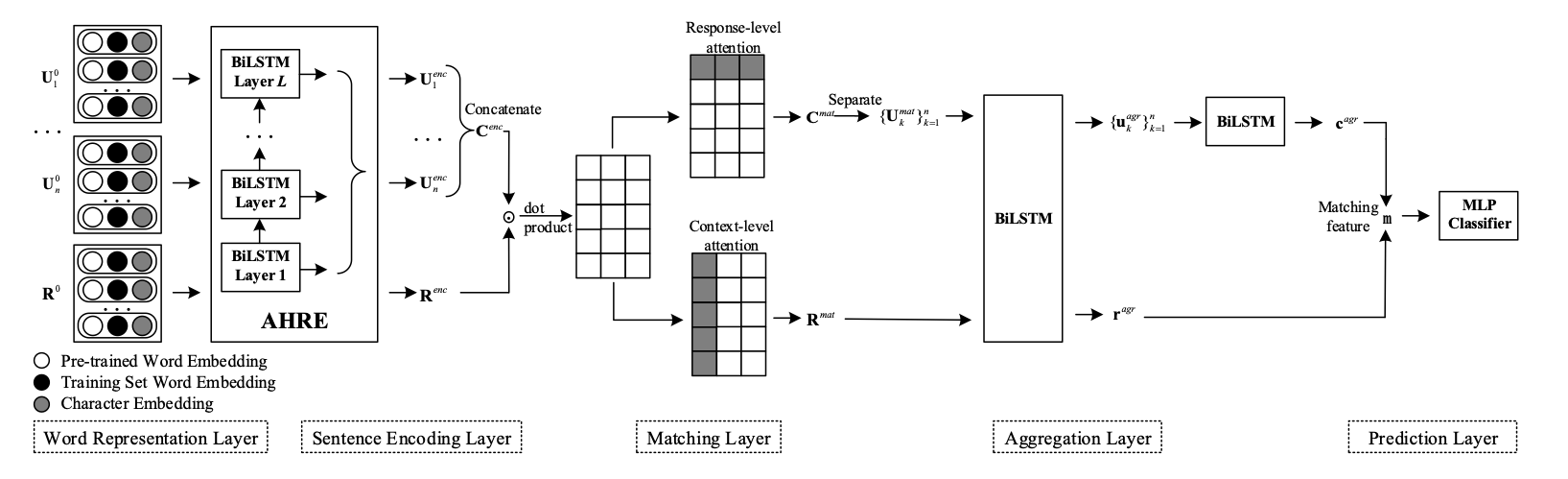
同样 IMN 的作者也想到了用character来减缓 OOV 的问题
创新点在于 EMbedding 层之后用了一个类似ELMo的处理策略 来获取 Sentence 之间的信息
(当然 如果现在来做 用 Bert 做同样的事情可能会更好)
除了上述的 idea 之外 作者还在 dot 完之后分成两个粒度做处理
仔细一想 这和 MRFN 的 FLS 本质上是一种思路 把 fusion 的过程往后推迟
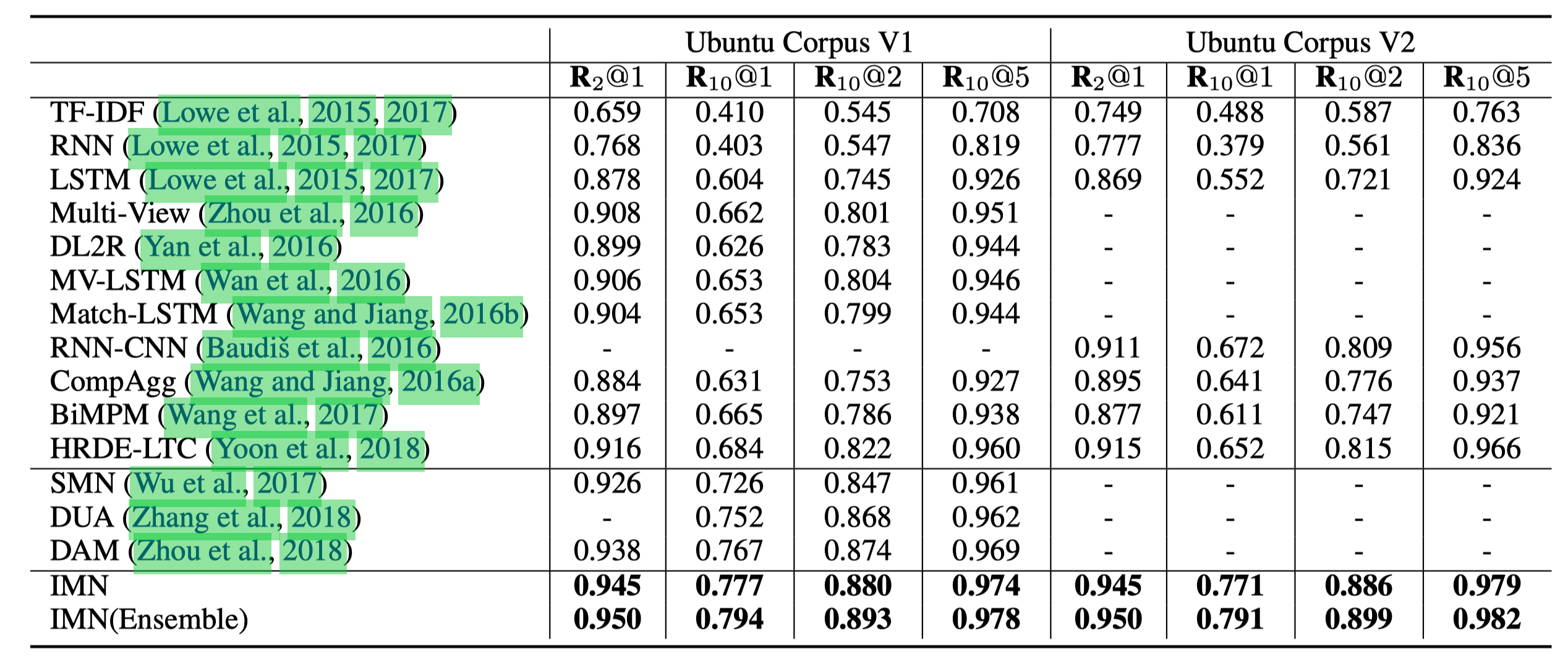
然后这个 result 确实厉害 ym dalao