多核操作系统中的自旋锁-『以XV6 & Linux 为例』
自旋锁是一个很神奇的东西,一个介于高效和低效之间的一个 『薛定谔』😯的互斥机制。
自旋锁的效率和它的应用场景有很大关系,在实际生产过程中,我们能在很多地方看见它的身影。
比如 Linux kernal 有挺多地方用到 spinlock、 Nginx 也有用到 spinlock, 但很多时候自旋锁在很多场景下并不能很好的发挥出它的高效优势。
究竟什么时候我们应该使用 SpinLock?
首先,要注意的是自旋锁只适用于多核心状态下(这个多核心指的是当前进程可用的核心数 > 1), 比如说你是一个 8 核 Mac,但是你在一个限制 1 核的 Docker 环境中用 SpinLock,卵用也没有!!!
本质上,SpinLock 之所以有效就是假定,当前存在另外一个 CPU 核心正在使用你所需要的资源。CPU 只有一个你等也是白等。 (就好像一个痴汉暗恋一个人一样,划掉 🙃)
其次,SpinLock 之所以在一些场景下很高效是因为旋等消耗的时钟周期远小于上下文交换产生的时间。
我们来回顾一下 Mutex 睡眠等待的过程。首先是尝试上一次锁,如果不行的话就通过调度算法找到一个优先级更高的 Thread,然后才是保存寄存器,写回被修改的数据,然后才是交换上下文。
可以看到这个代价是十分大的,而且交换上下文的代价是要 ✖️2 的。一般来说,这个代价,在几千~几十万时钟周期。回顾一下一个 4GHz 的 8 代处理器,一个时间周期=0.25ns。交换一次的代价还是挺可观的。
所以我们使用 SpinLock 的时候就需要保证我们的临界区代码,能够在这个时钟周期之类完成所有任务。
所以一般 spinLock 等待的代码不会太长,一般几行(具体需要看芯片和编译环境),更不可能是 I/O 等待型的任务。(在 XV6 中,关于文件系统的操作都单独使用基于 SpinLock 的 SleepLock)
然后,其实 SpinLock 更适合系统态,不太适合用户态。因为你用户态没法知道有没有另外一个 CPU 在处理你所需要的资源。而且 SpinLock 并不适合多线程抢占一个资源的场景,比如说开了 60 个线程抢占一个一个内存资源,这个竞争、等待的代价就是超级大的一个数。
所以,其实自旋锁的优势、劣势都很明显,怎么来更好的用好它就是程序员 👨💻 的事情啦。
SpinLock in XV6
XV6 其实是一个很 Unix 的教学操作系统,通过对 XV6 代码的阅读,我们其实能够以更少代价来了解 Unix 是怎么做的。
SpinLock 在 XV6 中定义在<spinlock.h>和<spinlock.c>两个文件中,实际上代码量不过 100 行,是很好的分析案例。

首先, SpinLock 类中用了一个 unsigned int 来表示是否被上锁,然后还有 lock 的名字,被哪个 CPU 占用,还记录了系统调用栈(这个实际上就是完全用来调试用的,当然一个健壮的 OS 需要方方面面考虑到)。

当我们需要去获得这个锁的时候,它会先去关中断,再去检查这个锁有没有被当前的 CPU 占用,然后是一个尝试上锁的循环,最后是标记被占用的 CPU,记录系统调用栈。
总的来说思路比较清晰,我们来看一下具体实现细节。

pushcli 函数是用来实现关中断过程的一个函数,先会去调用 readeflags 这个函数来读取堆栈 EFLAGS, 然后调用 cli 来实现关中断。
如果是第一个进行关中断的(嵌套关中断数是 0),则还会去再 check 一下 elfags 是不是不等于关中断常量FL_IF。
而 readeflags()和 cli()这两个函数都是通过内联汇编来实现的。

readeflags, 就是先去把 efalgs 寄存器当前内容保存到 EFLAGS 堆栈中,然后把 EFLAGS 堆栈中的值给到 eflags 变量。

而 cli()就很简单粗暴的调用 cli 汇编指令。

当我们关中断之后,会去检查当前 CPU 有没有持有这个 SpinLock。

如果已经持有这个 SpinLock 则会退出。
当完成这一系列常规操作之后,才是最关键的获取锁的步骤。

他会去调用 xchg()这个内联汇编函数。会去执行lock; xchgl %0, %1这个汇编代码。
最关键的实际上是xchgl这个指令, 从效果上看 xchgl 做的是一个交换两个变量,并返回第一个变量这个事情。
实际上这个指令,首先是一个原子性的操作,当然,这我们可以理解毕竟是多核状态,如果有好几个 CPU 核心来抢占同一个 SpinLock,需要保证互斥性, 需要排他来访问这块内存空间。
其次 xchgl 是一个 Intel CPU 的锁总线操作,对应到汇编上,就是自带 lock 指令前缀,就算前面没有加lock; 这个操作也是原子性的。
其次,既然是锁总线操作,就有可能失败,这个命令式非阻塞的,每次执行只是一次尝试,所以这个 while 就说的通了。通过循环尝试上锁,来实现旋锁机制。
最后,这条命令还用到了一个 read-modify-write 的操作,这个操作,主要是因为在现代 CPU 中基本上都会使用 Out of Order 来对指令执行进行并行优化。
但是我们这个加锁的过程是一个严格的时序依赖过程,我们必须保证,前面一个 CPU 加上了锁,后面 CPU 来查询的时候都显示已经上锁了。即 read-modify-write 顺序执行。
在 XV6 和 后面分析的 Linux 实际上都是用__sync_synchronize来实现这个过程的。
至此,XV6 SpinLock 最关键的部分就解读完了。
当已经拿到 SpinLock 的时候,就回去更新 cpu,call stack 来给 DeBug 使用。
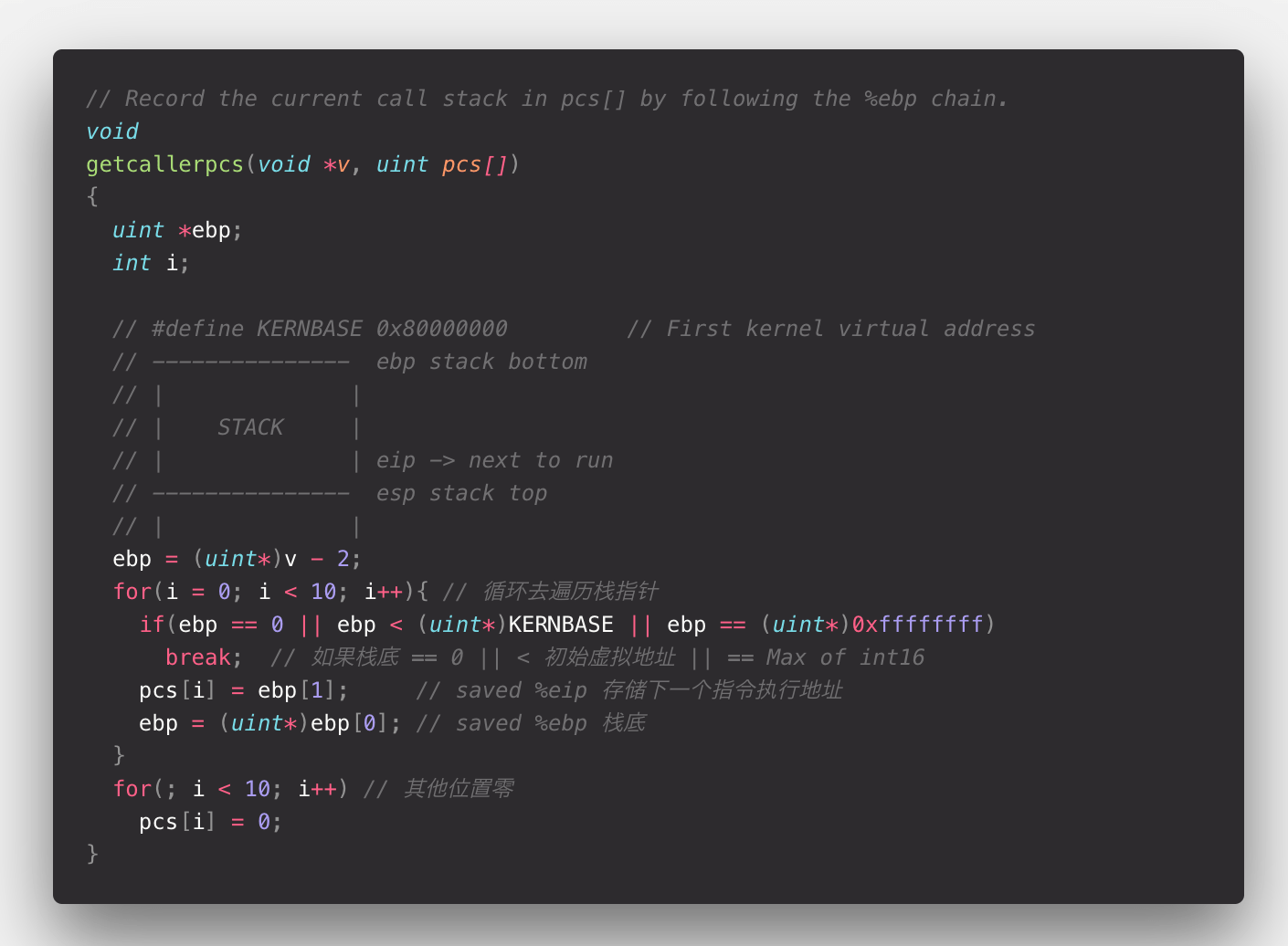
实际上这段代码是依次向前遍历,来获得栈底 EBP,栈顶 ESP,下一个指令地址 EIP 地址。
释放也是相同的套路。

先去康康你这个 SpinLock 是不是已经被释放了,然后取清空 call stack, cpu,最后再来修改 locked 位。
这个地方就不用旋等,因为一个 SpinLock 只会被一个 CPU 占用。
最后是关中断

还是一样去检查 ELFAGS 堆栈和中断可用常量相不相等。
检查当前 CPU 的嵌套中断数是否大于 0.
然后再来检查 cpu 中断标志是否不为 0,最后再来开中断
SleepLock in XV6
前面说到,实际上 SpinLock 不适用于临界区是 I/O 等待的情况,所以在 XV6 中,关于文件系统的锁机制是用 SleepLock 来实现的。
SleepLock 定义在<proc.c>文件中
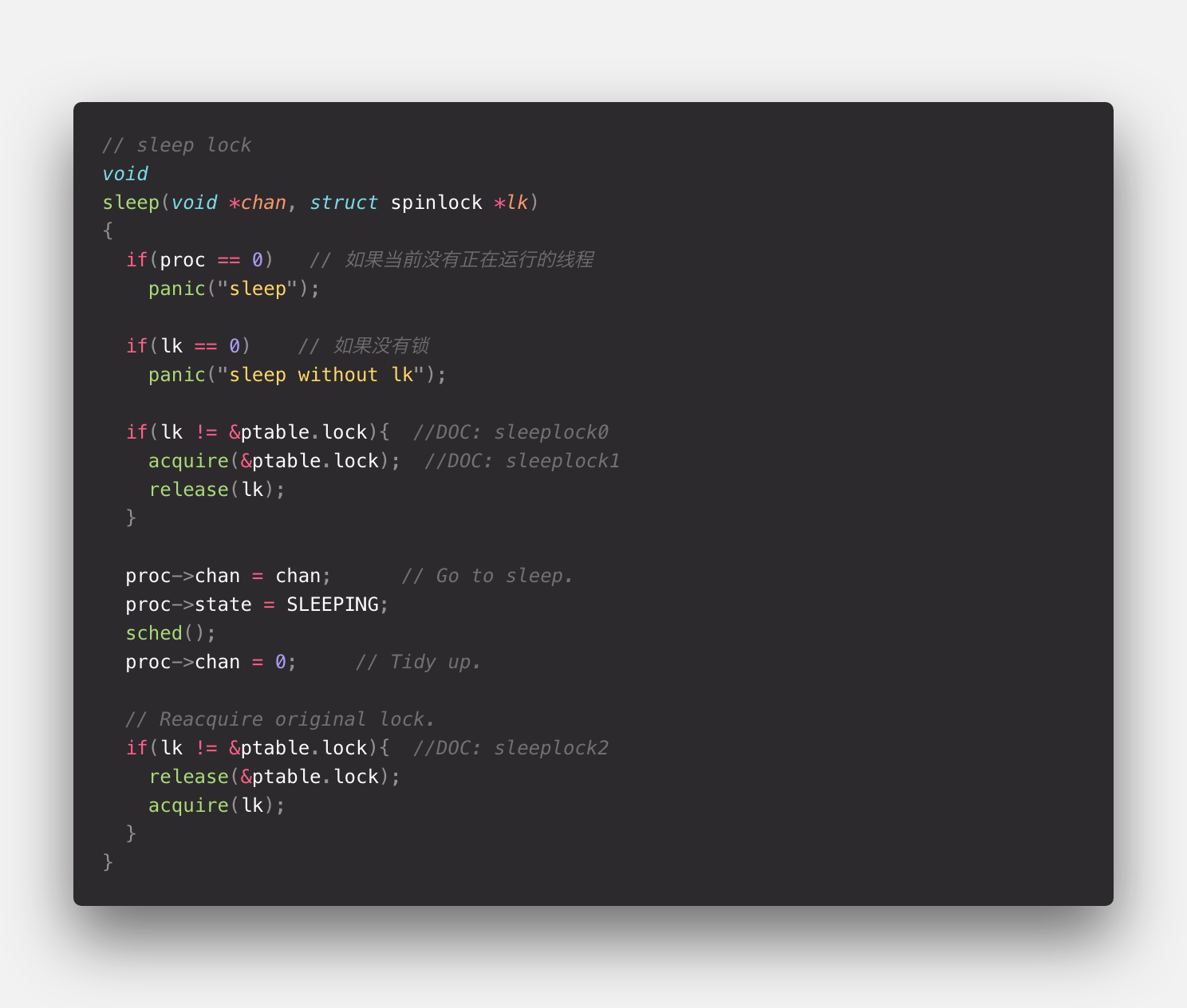
在这里在常规检查之后,并没有之前去请求 SpinLock, 而是先去获取 ptable.lock(这也是一个 SpinLock)。因为逻辑不相干,所以这个 ptable.lock 更容易获得。
然后释放 SpinLock,以便造成堵塞。然后记录下睡眠前状态,把 CPU 交给调度程序来调度。直到被调度回 CPU,先去释放之前占用的 ptable.lock, 然后再来获取真正需要的 SpinLock。
从而实现睡眠锁,可以看到这个这个睡眠锁实际上相关于用另外一个 SpinLock 来做通知的作用,相当于去抢占另外一个不是特别稀缺的资源。

而调度函数sched() 则是依次去检查是否已经释放了 ptable.lock,检查当前 cpu 的嵌套中断数,检查 proc 的状态,检查 EFLAGS 堆栈。最后才是 switch 上下文。
SpinLock in Linux
看完 XV6 的 SpinLock 实现,再来看 Linux 的 SpinLock 实现,就会发现惊人的相似。
本文用 Linux kernal 版本号是4.19.30.

其实 Linux 下 SpinLock 的实现有好多种,上次分析了 tryLock,这次来分析最基本的 SpinLock.
Linux 的 SpinLock 的 Locked 是一个叫做 slock 的变量,具体 class 定义就不放了,上锁的函数在
spin_lock 会去调用 raw_spin_lock。而 raw_spin_lock 这个函数式指向_raw_spin_lock.
而_raw_spin_lock 则是一个随着运行环境不同的函数。
当处于非 SMP 环境时,实际上就变成了一个简单的禁用内核抢占。
而 SMP 环境中,则会去调用__raw_spin_lock 函数,而这个函数才是真正的实现上锁功能的函数。
大概思路和 XV6 基本一致,先去关中断,然后锁的有效性,最后再去真正的上锁。
而上锁这个函数 LOCK_CONNECT()则是不同环境有不同的实现。
Linux kerenal 中 总共有 15 个实现,(不知道有没有数错)然后以其中几个为例来具体分析。
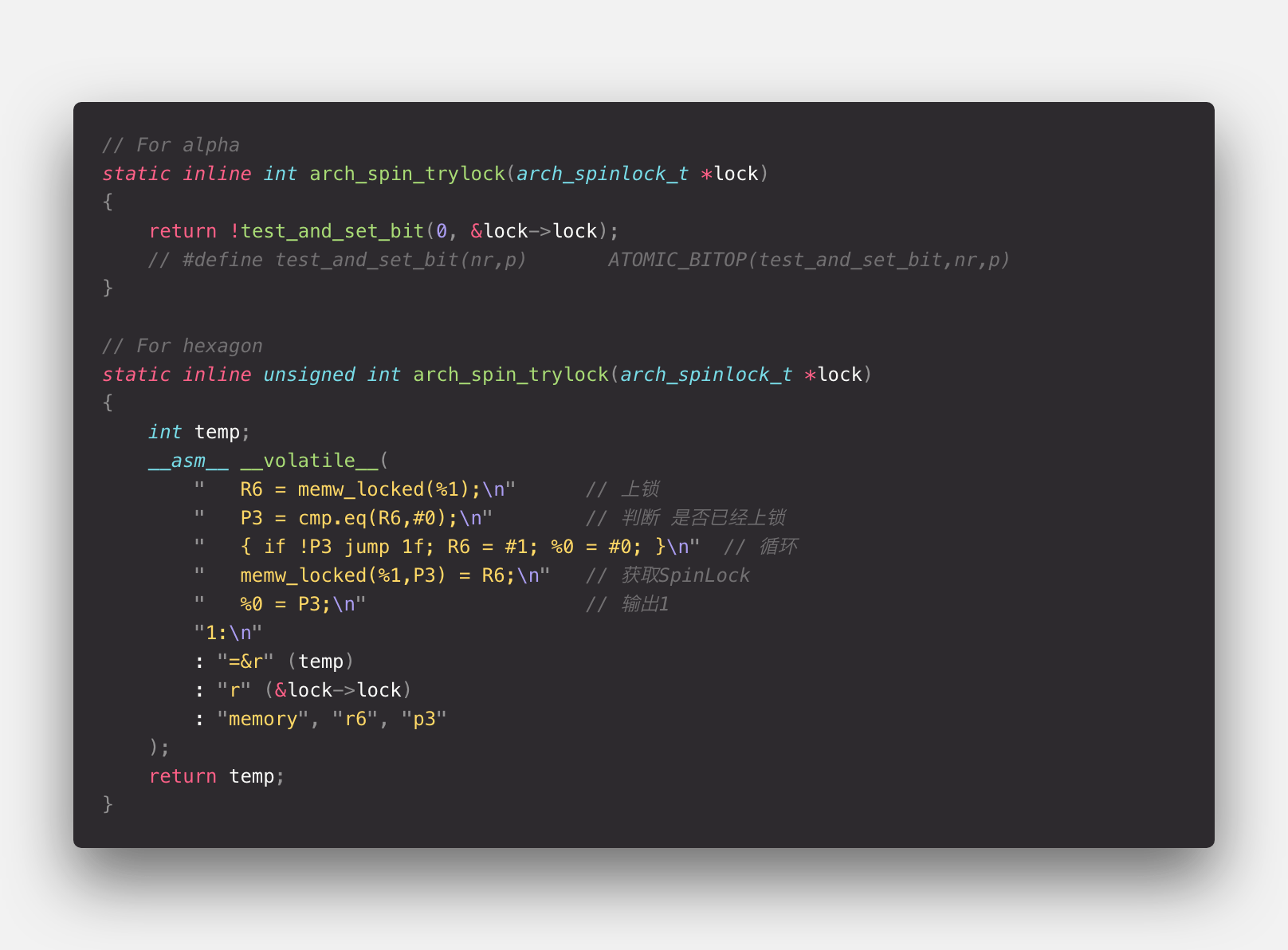
以<arch/arc/include/asm/spinlock.h>为例

这个版本的 arch_spin_trylock 先去声明一个__sync_synchronize(),这个操作和 XV6 中 read-modify-write 中一致。
然后相同是上锁,检查当前上锁状态,比较 Locked slock, 如果不满足条件则继续循环。
当成功上锁,则更改 got_it,并返回。
实际上这个操作流程和 XV6 几乎一样,同样的__sync_synchronize() 同样的判断加锁情况,附带循环比较。
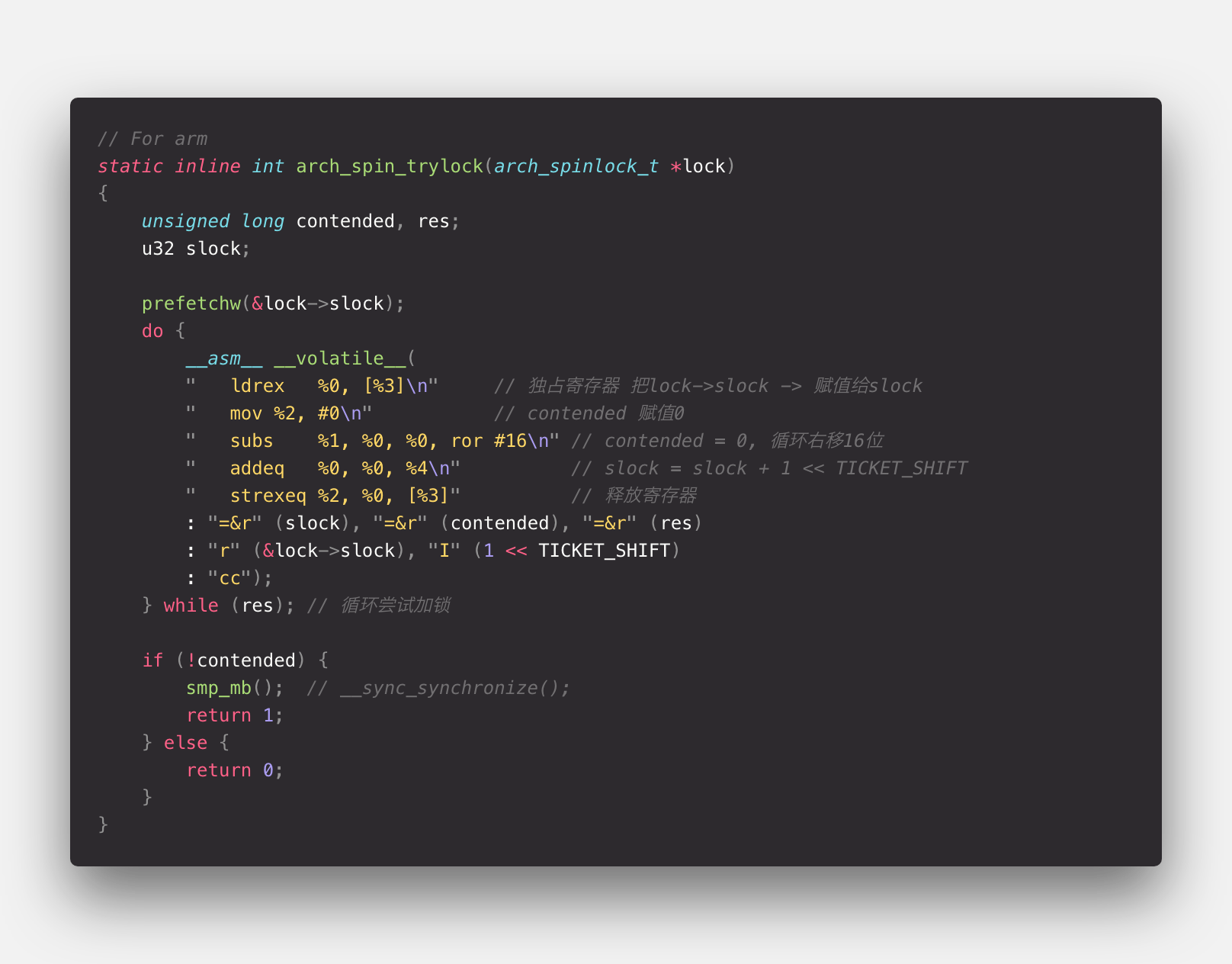
其他版本的 arch_spin_trylock 大概思路也是相同的, 贴一下部分版本解析。