如何用NLP技术和标题党说拜拜👋-文本摘要
拖延症 拖了一个星期 🤦♀️ 然后在查文献的时候 发现中文的资料比较少 于是
文本摘要 算是 NLP 领域一个还实用的细分领域吧
其实按我的理解 文本摘要 是一个披着NLP外衣的CV领域内容(至于为什么 请 dalao 往下面看)
想想一下 每每看见震惊 公交车上🚍 有男子做出如此不堪的事这样的标题
可能不自觉的就脑补 一些 你以为会发生的事
结果 点开 链接 发现 这根本就不是你想想的那会事
然后 你会痛骂一身标题党 小gg 然后默默的关闭了网页
如果在你点开链接之前 已经有一个整理好的概述 这个时候 是不是标题党 就一目了然了
文本摘要 解决的 就是 在大数据环境下 如何利用 NLP 技术 对文章进行概括
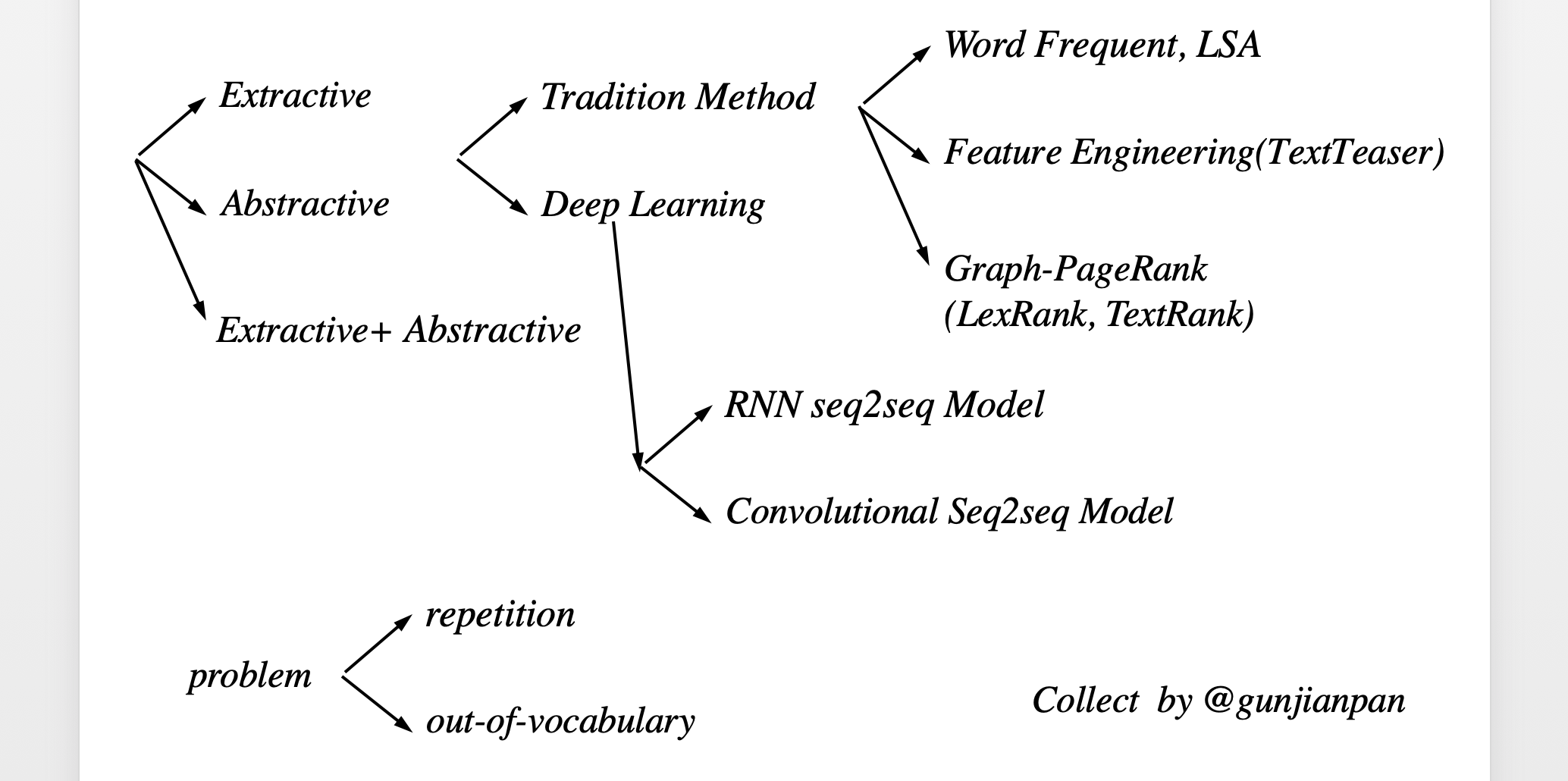
feature era
早在上世纪五十年代 就有学者开始研究Text Summarization问题 提出利用诸如词频 首段 首句 标题等等一些特征值 对文章进行自动化概括
本质上来说 这些 都是属于特征工程范畴的工作 利用一些人类认知上的明显的特征关系 找到文章与生成的摘要之间的匹配关系
当然可以想象到 纯人力挖掘 特征 能达到的效果有限
但限于 算力的制约 一直到近年 随着深度学习在 ImageNet 上崭露头角 才稍有起色
Extractive Vs Abstractive
因为我们已经对 NLP 领域问题分析的套路 已经有一些 认识
以上的 思路 主要是从 文本中原有信息 根据人类普遍意识上的认识 提取出对应于文章的一段文字 这是一种 Extractive 方法
很容易想到 除了 抽取之外 还可以通过对 NN Output 的参数 进行 decoder 操作 进行 Abstractive 操作
生成式的思维 其实 更 符合人类习惯 但 相对于 现有的技术而言 效果 会比较差
之前 我们 在多轮检索式对话中 分析的 也是抽取式的模型
我们对 检索式的大致套路 已经 有所 了解
先对 原有的文本做一个表示 可以是 word 粒度的 也可以是上下文粒度的
在 QA 问题上 从基于表示的思路变换到基于交互的思路
但 QA 问题和摘要问题 侧重点 不太一样
QA 更 能反映 NLP 问题的时序性 对话中 上一句 接着 下一句
在对话过程中 Topic 很重要 非停用词很重要 语言风格也很重要 但 Topic 可能变化 语言风格也可能变化 停用词 也许会变成至关重要的
对话系统侧重 抓取时序上的信息
而 Text summarization 这个问题中 侧重于 Topic 的挖掘 时序上的信息 变得没那么重要
直观上感受 文本挖掘 只要从一篇已有的文章中 从排好队的词阵列 中 抽取这篇文章最重要的词 组成它的摘要
这一点 就和 图像识别 很类似-从一张已有的图片中 根据像素分布 抽取出 能代表周围一块区域的特征
所以 目前 Text Summarization 领域中 效果比较好的还是 CNN 与 seq2seq 结合的模型
(当然 QA 也一样 会用到 CNN 那里的 CNN 做的 也同样是抽象的功能)
Extractive
抽取特征的思路 可以分为 抽取主题 和 抽取指示符
- 抽取主题 方法, 比如说 浅语义 LSA、LDA 词频 主题词 贝叶斯 et al.
- 这种方法 侧重于 试图 寻找语义上的 主题
- 指示符(你可以粗暴的理解为特征):
- 比如说: 句子长的可能是更重要的 在文档中位置靠前的可能更重要 具有 Title 中某些词的句子可能更重要
Extrative 然后 根据 这些 方法 对每个句子进行 一个评分的操作
然后一样的套路根据这个评分 召回可能重要的 k 个句子
再对这 k 个句子 做加工 比如说贪心的认为@1 的是这个文章的摘要 也有模型针对最大化整体一致性及最小化冗余进行优化
除了 抽取特征的思路之外 还有基于知识库(对 vertical domain 进行分析)
Topic Words
在 Toipic word 是的思路下 有诸如
- 词频阈值: 词频超过一个阈值的情况下 它就是主题词
- 主题签名词: 有些时候 主题 可以通过多种多样的词语表示 每个主题签名词的词频并不一定高
- 通过建立对数似然估计检验 来 识别 这些
主题签名词 - 可以是计算主题签名词数量的频次 (偏向长句子)
- 也可以是计算主题签名词的占比句子中总词数的比例 (偏向高主题词密度句)
- 通过建立对数似然估计检验 来 识别 这些
Frequent-driven
词频方法 较为简单 主要是直接算词频 或者 利用 Tf-Idf 计算词频
Latent Semantic Analysis
浅语义 主要 就是 做矩阵分解 计算 SVD 那么得到的中间矩阵就可以看作为原矩阵的 Topic
当然 LSA 之后 还有基于 Dirichlet 分布的 LDA
Graph Method
基于 PageRank 的思想 把文章 抽象为 graph 其中句子 代表 graph 中的节点 边权值则为句子和句子之间的相似度
最简单的相似度的做法 就是 Tf-idf
要想获得更好的效果可以 尝试 用一下 QA 中使用的基于基于交互、双向 GRU、Transform 等等办法
计算出 各边值之后 就按照 PageRank 的思路 计算 重要节点 这些重要节点 就是我们需要的摘要句子
讲到这里 我们不难想到 如何 把之前多轮检索式对话系统 中 用到的计算 context-reply 之间关联度的方法 用在这里
可能会有不错的效果 但 老年人 不能安逸与现状 对吧 检索式 我们做过了 生成式 还没有实践过 so 😭
Graph 方法 比较有名的 比如说 LexRank, TextRank
Mechanical Learning
本质上 抽取式文本摘要 也是 一个分类问题 把所有文本 分类为 是文本摘要 和 不是文本摘要的
分类问题 就有很多操作的空间 比如说 用朴素贝叶斯 决策树 SVM HMM
但 样本集标注信息 较难取得 故有学者提出半监督的模型
通过同时训练两个分类器 每次迭代时 把具有最高分的未标记训练集扔到标记训练集中 以此迭代
Abstractive
随着 NN 及 seq2seq 对机器翻译上表现出的显著提升
相应的技术也逐渐应用在Text Summarization领域上
实际上 在文本摘要这个领域中 很多技术是借鉴与机器翻译的
比如说受到 NMT(Neural Machine Translation)中 Attention 和 NN 的应用的启发,有学者提出 NNLM(Neural Network Language Model)结构
之后 有人用 RNN 代替 NNLM 比如说 ABS 什么的
在这样的模型中会出现几个问题
- 不能像抽取式一样获取到文本的重要消息
- 无法处理 OOV(out-of-vocabulary)问题
- 当然我觉得 OOV 是预处理不好产生的问题
- OOV 就是 test dataset 中存在 train model 建立的词表中没有的词
- 像这个问题 可以简单粗暴的把 OOV 用零向量或者
<UNK>代替 丢到 NN 中训练 - 也可以用 char-level 粒度的模型
- 要么优化你的分词器
- 再有就是用
FastText
- 然后还有一个比较关键的是词句重复
- Seq2seq 模型还会出现
exposure bias和训练与预测结果不一致Exposure bias指的是训练时,输出是有真实的输入决定的; 而预测时,输出由前一个生成的输出决定的,这就导致因为生成的误差累计造成最后一层输出较大的偏差训练和预测评价不一致是因为我们在评价这类问题使用的是不可微分的指标比如说 ROUGH,而 Loss 函数用的是对数似然估计不一致。这个可以通过强化学习(RL)来缓解- 有很多学者基于 RL 做了一些工作 有不错的结果
我们知道在 NLP 中 处理语句时序信息的分析 常见的套路就是 RNN 系 什么 LSTM Bi-LSTM GRU Bi-GRU
但在数据量比较的大的时候 比如说海量文本摘要分析这个问题上
RNN 因为要前后迭代 复杂度 较大 会出现梯度消失 梯度爆炸 💥 的问题 (其中有学者提出梯度范数裁剪解决这个问题)
因为Text Summarization 这个问题 没有 QA 那么强的时序性要求 实验发现利用 CNN 也有较好的效果
在这种 CNN-seq2seq 模型中 先用一个 encoder 的 CNN 把原文映射到 Hidden 层上去 然后根据这个 Hidden 层输出的值 再用一个 decoder 的 CNN 输出生成的摘要
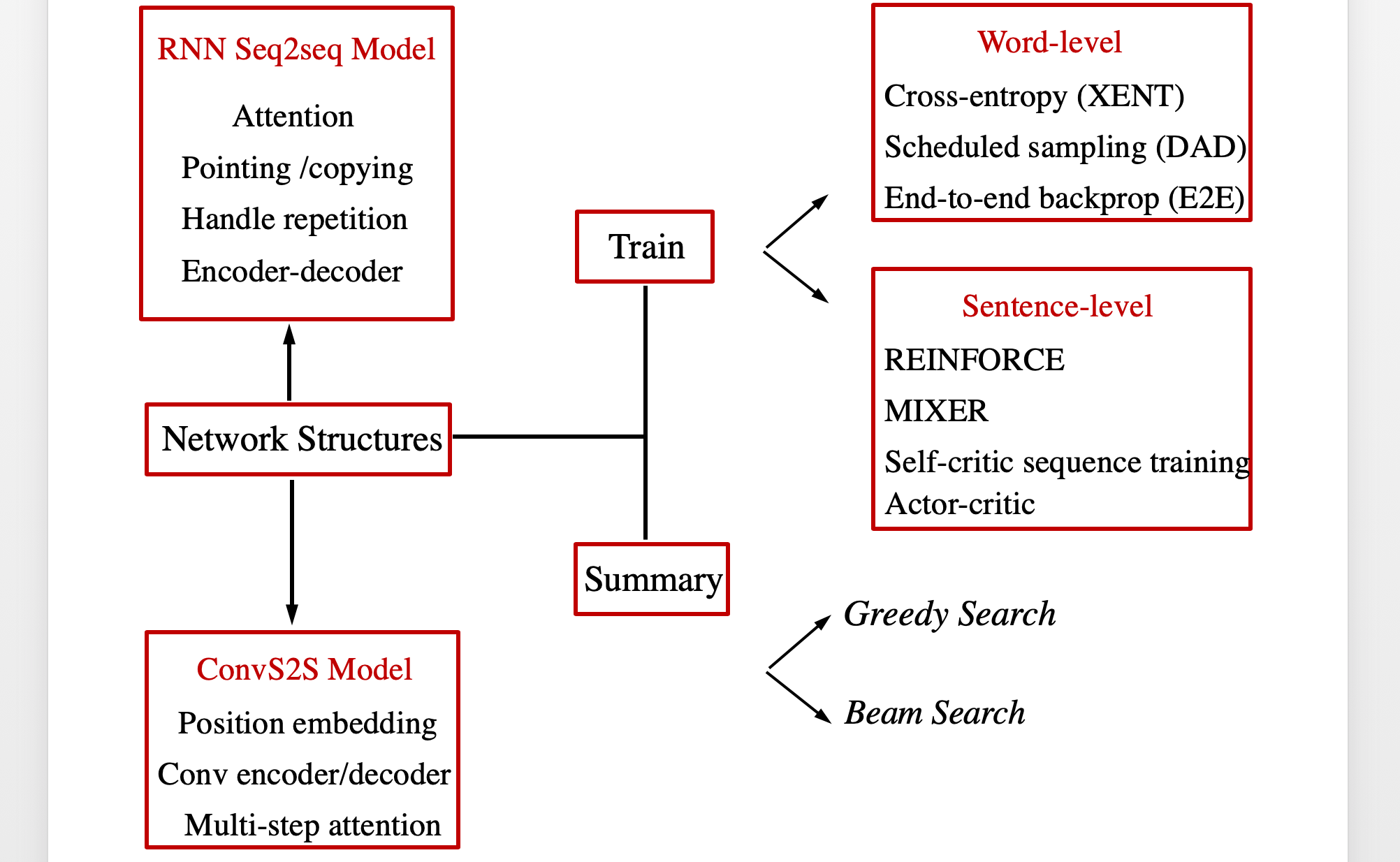
ConvS2S
[Jonas Gehring et.al. ICML 17]
ConvS2S = Convolutional Sequence to Sequence Learning
这篇论文是 Facebook 工作很久的产物 去年发出来 和 现在 Bert 差不多的效果
CNN 相较于 RNN 而言 可以并行 而且不会出现梯度消失 可以更好的选取长距离的信息(这 太像Transform了吧)
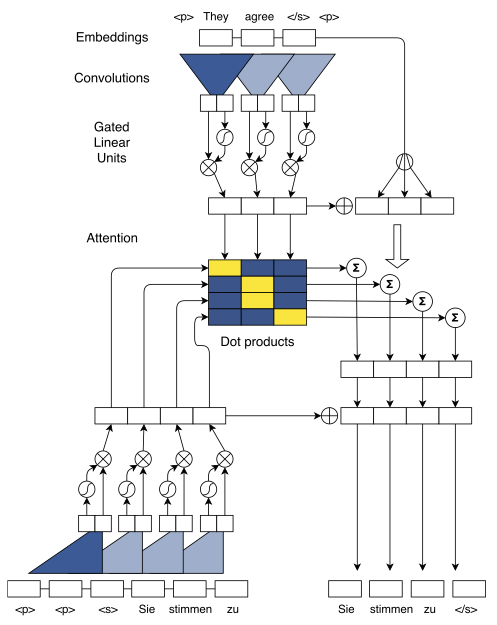
ConvS2S 采用的是带 Attention 的 Encoder-decoder 结构 其中 encoder 和 decoder 用的是相同的卷积结构
(在 ConvS2S 上面 我看到了 Bert 的影子)
首先 ConvS2S 采用了 Transform 或者说 Bert 中使用的Position Embedding 然后 也是和 Bert 一样 简单粗暴的把 Position Embedding 和 word Embedding 加和在一起
我们再来复习一下 Bert 可以发现 Bert 的 word Embedding 比他好一丢丢(类似完形填空的深度双向 Encoding) 除了上述两个 Embedding 之外 还加了一个句粒度的负采样Segment Embedding
只不过 在这里 处理好的 Embedding 是丢到 CNN 中训练 而不是丢到 Attention 中训练
在 ConvS2S 中 除了 传统的 CNN 之外 还有一层 Multi-step Attention
这里的 Attention 权重 是由当前层 decoder 输出 和 所有层 encoder 加权决定的
这样使得模型 在考虑下一个 decoder 的时候 之前已经 Attention 过的词 也能占到不少的权重
ConvS2S 使用 GLU 做 gate mechanism
然后 ConvS2S 还进行了梯度裁剪 权重初始值等优化 使得模型很快 很 work
最后将 decoder 输出与 encoder 的输出做 dot 构造 对齐矩阵
Topic-ConvS2S
[Shashi Narayan et.al. EMNLP 18]
这篇文章是爱丁堡大学的 dalao 在今年 EMNLP 上发表的成果
之前我们做的 Text Summarization 多少都用到点抽取到的信息即使是生成式的任务
这篇文章想完成一个极端概括的任务 把大段的文章用一句话概括
这个任务 就和 文章的 Title 不一样 Title 目的是让读者有兴趣 去阅读这篇文章
而概括这是需要考虑到散布在文章各个区域的信息
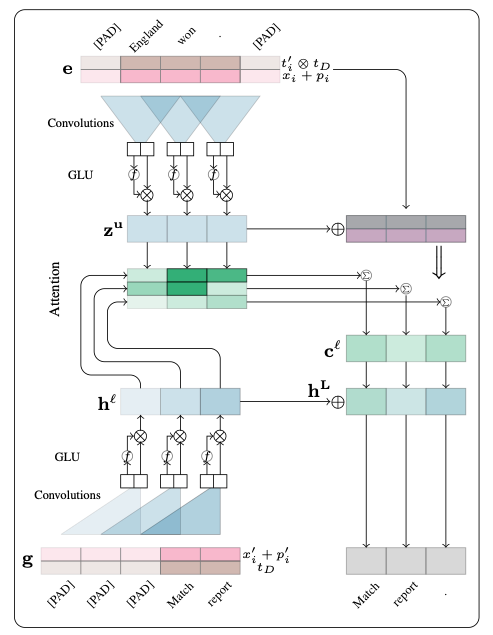
Topic-ConvS2S 主要的工作 一个是建立 XSum DataSet 然后就是把 Topic 和 ConvS2S 结合在一起
模型利用 LDA 获取一层Topic Sensitive Embedding
\begin{equation}e_i=[(x_i+p_i);(t_i'$⊗$t_D)]\in R^{f+f'}\end{equation}
其中$x_i$为 word Embedding, $p_i$为 Position Embedding, $t_i$为文档中单词的分布, $t_D$为文档中主题的分布
通过构造$e_i$来获取关于 Topic 的 Embedding 信息
其他的和 ConvS2S 基本一致 同样用到两个相同的encoder-decoder卷积结构 同样是Mult-step Attention 连图都很像是吧
RLSeq2seq
[Yaser Keneshloo et.al. sCCL 18]
前面我们 seq2seq 的使用时 会出现 Exposure Bias和训练与预测评价不一致的问题
强化学习就是来解决这个问题的一种方式
强化学习 就是 通过一些奖惩使得 向某一目标 学习 以期习得针对任意给定状态的最佳行动
在本模型的奖惩 就是 当生成完整个句子之后 通过 ROUGE 等评估方法得到的反馈
这样 原来因为 交叉熵计算出的 Loss 与 评价体系 Rough 不一致的问题 就能够 得到解决
Reinforced Topic-ConvS2S
[Li Wang et.al. IJCAL 18]
这篇是腾讯联合哥伦比亚、苏黎世联邦理工发布的基于 Topic-ConvS2S 的 Text Summarization论文
实际上 你可以发现 论文 基本和前面的 Topic-Convs2S 一致 只是增加了 RL 的内容
目测应该是同期论文 否则根本发布出去
虽然在 Topic 上面用的也是 LDA 一样是在预处理阶段对 Topic 进行划分
但前面的 Topic-ConvS2S 是把原来的 word Embedding 和 Topic 获得的信息 直接相加
在本文 利用一个 Joint Attention 再加上 Bias Probability 来实现与 word Embedding 的结合
之后 在 Loss 函数的地方 利用强化学习中 self-critical sequence training (SCST)
使得不可微分的 ROUGH 指标最大化
在训练过程中 根据输入序列 X 生成两个输出序列
我们先贪心地选择能使得输出概率分布最大的单词作为第一序列 y1
再加上从分布中采样中生成的另一个输出序列 y2
于是这两个序列获得的 ROUGE 分数则是强化学习的 Bonus
CAS
[Angela Fan et.al., ACL 18]
CAS = Controllable Abstractive Summarization
这篇论文 是之前 facebook 发 ConvS2S 那个团队的后续 工作
字面意思 就是 可控的生成式摘要
目前的文本摘要 对于所有人 显示的摘要 一样
但其实这是很不友好的 比如说一个吴亦凡 和 黄子韬 两个人的新闻 结果你只是吴亦凡的粉丝 不想看到涛涛相关的内容
这个时候 就需要 能够控制 Text Summarization 长度 内容的摘取
文章从下面几个角度 对个性化进行研究
- Length-Constrained
- Entity-Centric
- Source-Specific
- Remainder
Evaluation
实际上 文本摘要 问题在模型效果判断上面 较为难处理
目前来说 Rough 效果一般 但总不能用人工评价吧
Rough 是一个模型评价集合,其中
- Rough-n 基于召回率的评估,预测结果与参考摘要之间的公共 n-gram 数/参考摘要内的 n-gram 数
- Rough-L 基于最长公共子序列 LCS 公共子序列越长 evaluation 越高
- Rough-SU 可不连续的 bi-gram 和 uni-gram 相较于 Rough-n 不要求 gram 连续
Reference
- Text Summarization Techniques: A Brief Survey [
Mehdi Allahyari et al. Eccv 2017] - Neural Abstractive Text Summarization with Sequence-to-Sequence Models [
Tian Shi et al. 2018] - Convolutional Sequence to Sequence Learning [
Jonas Gehring et.al. ICML 17] - Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization [
Shashi Narayan et.al. EMNLP 18] - Deep Reinforcement Learning for Sequence-to-Sequence Models [
Yaser Keneshloo et.al. sCCL 18] - A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization [
Li Wang et.al. IJCAL 18] - Controllable Abstractive Summarization [
Angela Fan et.al., ACL 18]