『HDFS』伪分布式Hadoop集群
本文是『Hadoop』MapReduce 处理 日志 log(单机版)的旭文, maybe 还有后续
在搭建环境的时候发现很难搜到合适的教程,所以这篇应该会有一定受众
伪分布式就是假分布式,假在哪里,假就假在他只有一台机器而不是多台机器来完成一个任务, 但是他模拟了分布式的这个过程,所以伪分布式下 Hadoop 也就是你在一个机器上配置了 hadoop 的所有节点
但伪分布式完成了所有分布式所必须的事件
伪分布式 Hadoop 和单机版最大的区别就在于需要配置HDFS
HDFS
HDFS = Hadoop Distributed File System
当数据量超过单个物理机器上存储的容量,管理跨越机器的网络存储特定操作系统被称为分布式文件系统,HDFS 就是这样一种系统
HDFS 集群主要由 NameNode 管理文件系统 Metadata 和从机 DataNodes 存储的实际数据
NameNode = Hadoop Master, DataNodes = Hadoop Slave
- NameNode: NameNode 即系统的主站
- 其维护所有系统中存在的文件和目录的文件系统树和元数据
- DataNode : DataNodes 作为从机,每台机器位于一个集群中,并提供实际的存储,它负责为客户读写请求服务
HDFS 中的读/写操作运行在一个个块中,块作为独立的单元存储
之前我们提到这些块都是逻辑上划分的,只是用一个索引记录块的始末,并未真正的划分块
在 Hadoop 1.x 中 block 默认 size=64M,而 Hadoop 2.x 中默认 size 改为 128M
如果想重新定义block.size
$ vim etc/hadoop/hdfs-site.xml
# add
<property>
<name>dfs.block.size</name>
<value>20971520</value> # 其中该值为字节B数,且需要满足>1M=1048576=1024×1024, 且能被512整除
</property>
2
3
4
5
6
7
HDFS 是可容错的,可伸缩的,易于扩展,高可用的
HDFS 读操作
HDFS 这个系统除了主机和从机之外,还包括 client 端,file system
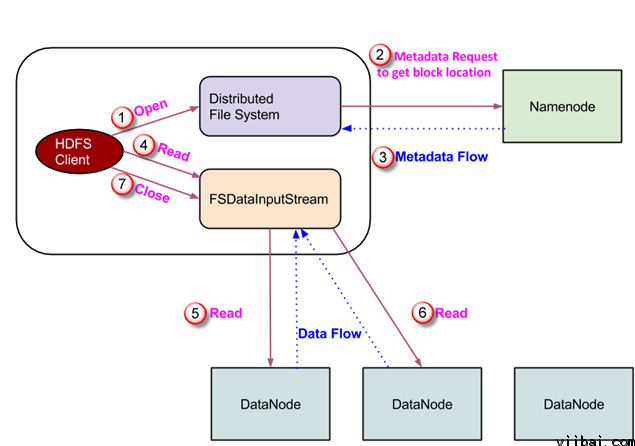
当客户端想读取一个文件的时候,客户端需要和 NameNode 节点进行交互,因为它是唯一存储数据节点元数据的节点
NameNode 规定奴隶节点的存储数据的地址跟位置
客户端通过 NameNode 找到它需要数据的节点,然后直接在找到 DataNode 中进行读操作
考虑到安全和授权的目的,NameNode 给客户端提供 token,这个 token 需要出示给 DateNote 进行认证,认证通过后,才可以读取文件
由于 HDFS 进行读操作的时候需要需要访问 NameNode 节点,所以客户端需要先通过接口发送一个请求,然后 NameNode 节点在返回一个文件位置
在这个过程中,NameNode 负责检查,该客户端是否有足够的权限去访问这组数据?
如果拥有权限,NameNode 会将文件储存路径分享给该客户端,与此同时,namenode 也会将用于权限检查的 token 分享给客户端
当该客户端去数据节点读文件的时候,在检查 token 之后,数据节点允许客户端读特定的 block. 一个客户端打开一个输入流开始从 DataNode 读取数据,然后,客户端直接从数据节点读取数据
如果在读取数据期间 datanodes 突然废了,这个客户端会继续访问 Namenode, 这是 NameNode 会给出这个数据节点副本的所在位置
HDFS 写操作
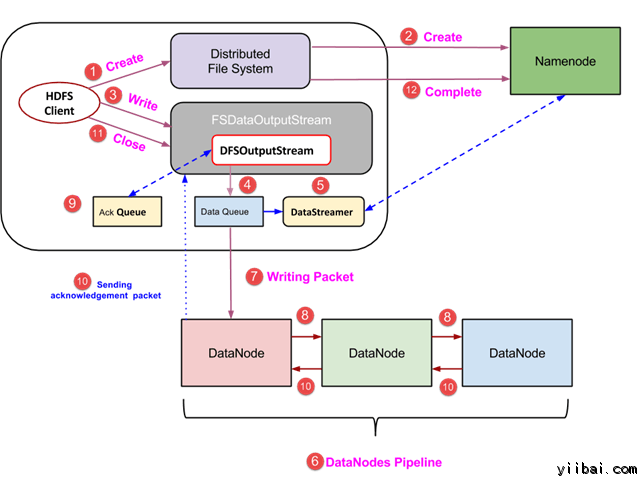
我们知道读取文件需要客户端访问 Namenode. 相似的写文件也需要客户端与 NameNode 进行交互,NameNode 需要提供可供写入数据的奴隶节点的地址
当客户端完成在 block 中写数据的操作时,这个奴隶节点开始复制自身给其他奴隶节点,直到完成拥有 n 个副本(这里的 n 为副本因子数)
当复制完成后,它会给客户端发一个通知,同样的这个授权步骤也和读取数据时一样
当一个客户端需要写入数据的时候,它需要跟 NameNode 进行交互,客户端发送一个请求给 NameNode, NameNode 同时返回一个可写的地址给客户端
然后客户端与特定的 DataNode 进行交互,将数据直接写入进去。当数据被写入和被复制的过程完成后,Datanode 发送给客户端一个通知,告知数据写入已经完成
当客户端完成写入第一个 block 时,第一个数据节点会复制一样的 block 给另一个 DataNode, 然后在这个数据节点完成接收 block 之后,它开始复制这些 blocks 给第三个数据节点
第三个数据节点发送通知给第二个数据节点,第二个数据节点在发送通知给第一个数据节点,第一个数据节点负责最后通知客户端
不论副本因子是多少,客户端只发送一个数据副本给 DataNode, DataNode 完成后续所有任务的复制工作
所以,在 Hadoop 中写入文件并不十分消耗系统资源,因为它可以在多个数据点将 blocks 平行写入
HDFS 配置
# 修改为主机名
$ vim etc/hadoop/slaves
# 添加主机名
$ vim /etc/hosts
2
3
4
# create folder
$ mkdir -p /usr/local/hadoop/tmp
# 修改temp地址
$ vim etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> ## localhost填主机名->主机名也是一个坑
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
# create folder
$ mkdir -p /usr/local/hadoop/dfs/name
$ mkdir -p /usr/local/hadoop/dfs/data
# 修改分布式储存配置
$ vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>10</value> ## node数
</property>
<property>
<name>dfs.block.size</name>
<value>20971520</value> ## block.size
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# yarn 配置,注意所有localhost为主机名,需保持一致
$ vim etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>localhost:8090</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
完成上述配置之后,需要对 FS 进行相应的格式化操作
hdfs namenode -format
hdfs getconf -namenodes
2
然后就可以启动 hdfs 了
$ bash sbin/start-all.sh
启动之后可以通过 Jbs 命令查看进程
也可以通过http://ip:50070进入HDFS的前端进行文件管理
报错 FAQ
- Hadoop 3.1.1 版本在 bash sbin/start-dfs.sh 会报bash v3.2+ is required. Sorry.
这个没法解决,搜了好多都没有答案,把包换成 2.9.1 就好了 PS: 记得把所有环境变量,软链接都改一遍
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
2
3
配置环境变量
$ vim ~/.zshrc
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
$ source ~/.zshrc
2
3
4
5
6
7
$ vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/etc/local/java/xxx ## 绝对路径
2
$ vim ~/.zshrc
PATH=$PATH:/usr/local/hadoop/sbin
$ source ~/.zshrc
2
3
$ export HADOOP_CONF_DIR = $HADOOP_HOME/etc/hadoop
$ echo $HADOOP_CONF_DIR
$ hdfs namenode -format
$ hdfs getconf -namenodes
$ etc/hadoop/start-all.sh
2
3
4
5
hdfs 系统和外部文件系统不同步,需要手动把文件传进去, hdfs 有一套类似于外部文件系统的 fs 命令
$ hadoop fs -mkdir -p /user/log/input
$ hadoop fs -put <datafile> /user/log/input
2
文件也可以在http://ip:50070中查看
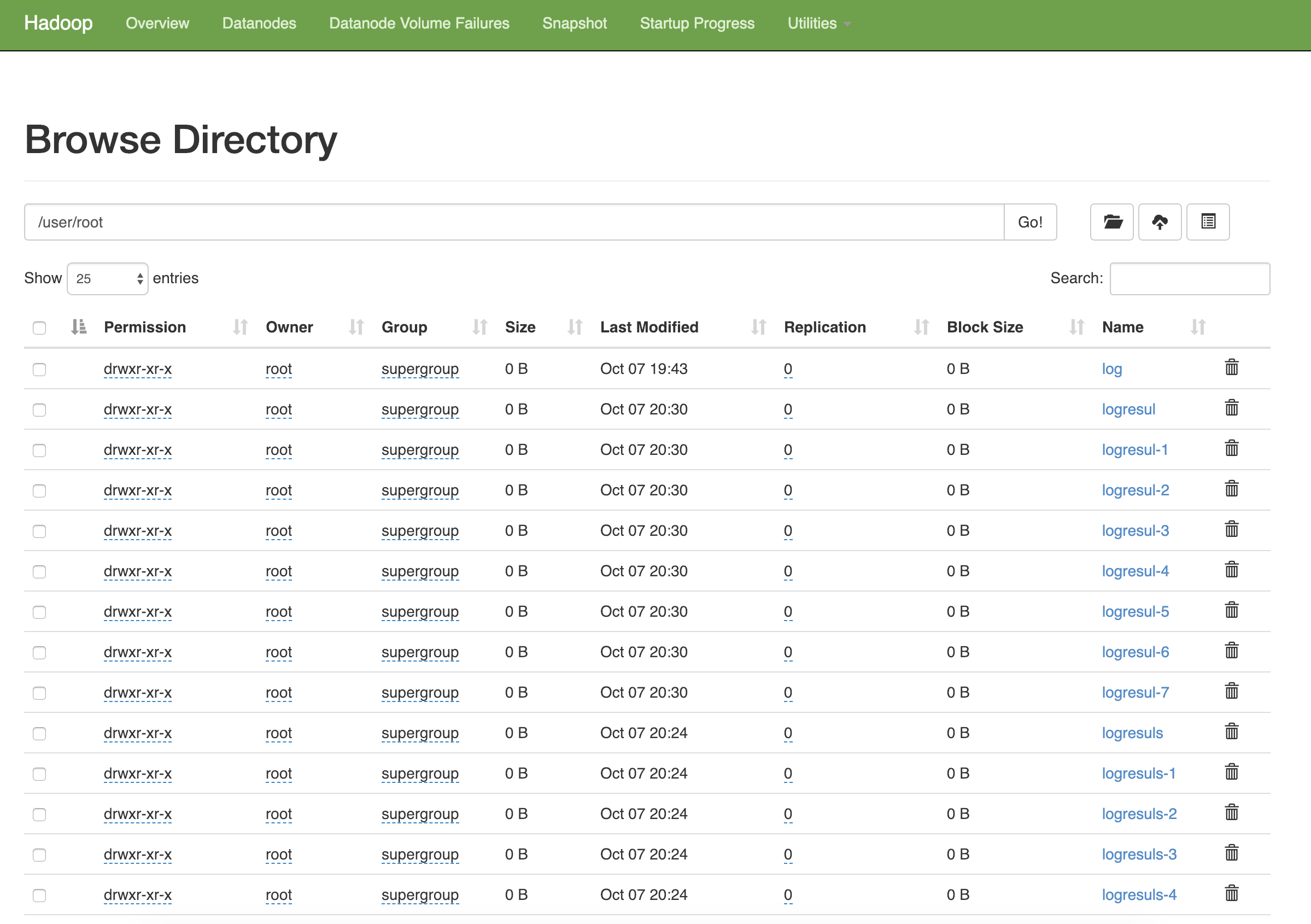
$ hadoop fs -ls /
$ hadoop fs -put < local file > < hdfs file >
$ hadoop fs -moveFromLocal < local src > ... < hdfs dst >
$ hadoop fs -copyFromLocal < local src > ... < hdfs dst >
$ hadoop fs -get < hdfs file > < local file or dir>
2
3
4
5
性能对比
单机版
Reduce input groups=1
Reduce shuffle bytes=14
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=33
Total committed heap usage (bytes)=291282944
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2977
File Output Format Counters
Bytes Written=18
spend:21559ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
伪分布-1 节点,block.size=10M
Map input records=180
Map output records=180
Map output bytes=1080
Map output materialized bytes=14
Input split bytes=106
Combine input records=180
Combine output records=1
Reduce input groups=1
Reduce shuffle bytes=14
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=31
Total committed heap usage (bytes)=287883264
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2941
File Output Format Counters
Bytes Written=6
spend:23277ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
伪分布-10 节点,block.size=20M
ted successfully
18/10/07 22:51:57 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=683924
FILE: Number of bytes written=8139284
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=281872252
HDFS: Number of bytes written=181666
HDFS: Number of read operations=181
HDFS: Number of large read operations=0
HDFS: Number of write operations=88
Map-Reduce Framework
Map input records=180
Map output records=180
Map output bytes=1080
Map output materialized bytes=14
Input split bytes=106
Combine input records=180
Combine output records=1
Reduce input groups=1
Reduce shuffle bytes=14
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=39
Total committed heap usage (bytes)=287825920
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2941
File Output Format Counters
Bytes Written=6
spend:24229ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
总的来说因为在一台机子上, 伪分布性能并没有提升
但跑起来 我那台破服务器 内存就跌零了 恐怖 😱
不充钱怎么变得强大