大图中如何快速计算PPR
终于写完了 花了快一周 累 拖延症的无奈
然后 发现 知识点好多 害啪
回想一下 现在 ML 领域逐渐走向交叉态势 不应该再拘泥于一个小方向
还是要多学习
关键词:PPRTopPPRChernoff boundAlias MethodMulti-armed Bandit本文预计需要20-30min
首先我们应该对什么是 PageRank有了一定概念 没有的话请点 👈
\begin{equation}PR(u) =\alpha \sum\limits_{v \in N_{in}(u)}^N \dfrac{1}{N_{out}(v)}PR(v) + (1-\alpha) \dfrac{1}{n}\end{equation}
\begin{equation}\vec{PR}^{l \cdot T}=\alpha ^l\vec{PR}^{0\cdot T}P^l+\dfrac{1-\alpha}{n}\vec{1}^T(\alpha^{l-1}\cdot P^{l-1}+\cdot \cdot \cdot+\alpha P + I)\end{equation}`
PageRank 相当于站在上帝视角进行评价所有节点的重要程度值
必须遍历所有网络上的节点才能进行计算
实际上我们并不知道互联网有多大 也没法从全局的视角评价所有节点
当然也是为了更个性化的评价
于是就有学者提出 PPR
跟我念 PPAPPPAPPPR
PPR = Personal Page Rank value
以个人节点出发 计算 PageRank 值
\begin{equation}PPR_s(u) =\alpha \sum\limits_{v \in N_{in}(u)}^N \dfrac{1}{N_{out}(v)}PPR_s(v) + (1-\alpha) \dfrac{1}{n}\end{equation}
PPR 的公式和 PR 的没什么区别 只是 PPR 的值都是基于某一个节点 s 这样的话就对 PPR 的研究就可以分为两个维度
- 给定一个 Source S, 返回所有节点关于 s 的 PPR 值
- 给定一个 Source S, 返回 Top-K 节点关于 s 的 PPR 值
- 当然最笨的办法就是先把所有节点的值都算一遍 然后再排序 当然 想效率高一点一般不这么做
- 对于这种问题 如果 PPR 值比较小,那么对它的估计误差 就不是特别重要(当然不能误差到 Top-K)
- 很显然这个问题在实际生产过程中更具有价值
在计算 PPR 的时候 还是需要进行递归计算的
递归就需要停止边界
$|\tilde{\pi}(s,t)-\pi(s,t)|\le\epsilon\pi(s,t)$$\pi(s,t)\le\delta$(一般而言$\delta = O(1/n)$)举个栗子, 在选 Top-3 的时候
\begin{equation}\pi(s,v_1)=0.45 ,\pi(s,v_2)=0.2, \pi(s,v_3)=0.18, \pi(s,v_4)=0.17, \epsilon=0.1, \delta=0.01\end{equation}在
$\tilde{\pi}(s,v_1)=0.45,\tilde{\pi}(s,v_2)=0.2, \tilde{\pi}(s,v_4)=0.18$时,有$|\tilde{\pi}(s,v_4)-\pi(s,v_4)|\le0.1\pi(s,v_4), |\pi(s,v_4)-\pi(s,v_3)|\le0.1\pi(s,v_3)$分别为收敛性和相似性不再 care top-K 后面的排序和值是否是对的
PPR 的有极强的工业应用场景 (就是给的钱多)
比如说鹅厂王者荣耀的好友推荐就是基于 PPR 的 (一般人我不跟他说)
A 厂主营业务 TB 的『千人千面』算法
还比如说实体消歧 (消除歧义 我第一次听见这个名词的时候也是一脸懵逼的)
还有社交网络的关系查询 羡慕 这么好找工作的实验室
当然 PPR 复杂度较高 所有有一些对它的近似估计算法 下面就来大致介绍一下 👇
Monte Carlo Method
[Andersen et al. 2007]
那什么是蒙特卡洛 简单来说 蒙特卡洛就是一类随机算法
一般把蒙特卡洛和拉斯维加斯放在一起比较
蒙特卡罗算法:采样越多,越近似最优解拉斯维加斯算法:采样越多,越**有机会***找到*最优解
举个很经典的 🌰
蒙特卡洛就是: 从 100 个 🍎s 中挑最大的,拿一个在手上,再随机挑一个,选二者最大的,除非遍历到最后一个,否则只能给出一个近似最优解拉斯维加斯就是: 从 100 把 🔑 中找到能开门的钥匙,不能保证一定找得到解,但找到了肯定是最优解
那么这里的MC算法就是以随机游走的概率估计 PPR 值 (其实相同的方法我们在 PageRank 的计算中也提到过)
那么这样的估计就是一个无偏估计 每次 Random walk 都是对所有点的无偏估计!
可以感觉出来 Random walk 越多估计的就越准
对固定一个点 每次 Random Walk 的结果之间都是独立的
那么就可以利用Chernoff bound(切尔诺夫界限)你可以把它理解为一个大数定理一样的东西
- 对任意
${x_i}\in[0,1](i\in[1,n_x])$, 均值为$\mu$的随机变量, 有\begin{equation}Pr\left\{|\sum\limits_{i=1}^{n_x}x_i-n_x\mu|\ge n_x\epsilon\right\}\le exp(-\dfrac{n_x\dot{}\epsilon^2}{2\epsilon/3+2\mu})\end{equation}
假设 Random walk 的次数$\ge O(\dfrac{\ln{n}}{\epsilon^2})$
那么达到停止条件$|\tilde{\pi}(s,t)-\pi(s,t)|\le \epsilon$的概率至少$1-\dfrac{1}{n}$
则带入Chernoff bound得到$exp(-\dfrac{n_x\dot{}\epsilon^2}{2\epsilon/3+2\mu})< O(\dfrac{1}{n})=\delta$
则推出Random walk实验次数$n>-\dfrac{c}{\epsilon^2}\log{\delta}=O(\log{n})$
然后这个过程也算是一个 PAC 过程
PAC =Probably Approximately Correct
达到 0 误差是非常困难 而且没有必要的 所以需要争取误差比较小$\le \epsilon$ 得到近似正确的概率比较大$\ge 1-\delta$
Forward Search
[FOCS’06]
每个 node 包含
Reserve:$\pi_f(s,v)$随机游走到 v,且停在 vResidue:$r_f(s,v)$随机当前游走到 v,不停- 在递归过程中
$r_f(s,v)$代表着未分配的概率值
- 在递归过程中
举个 🌰 ,如图 每个节点转移出去的概率为$1-\alpha$, 留在节点的概率为$\alpha$, 则
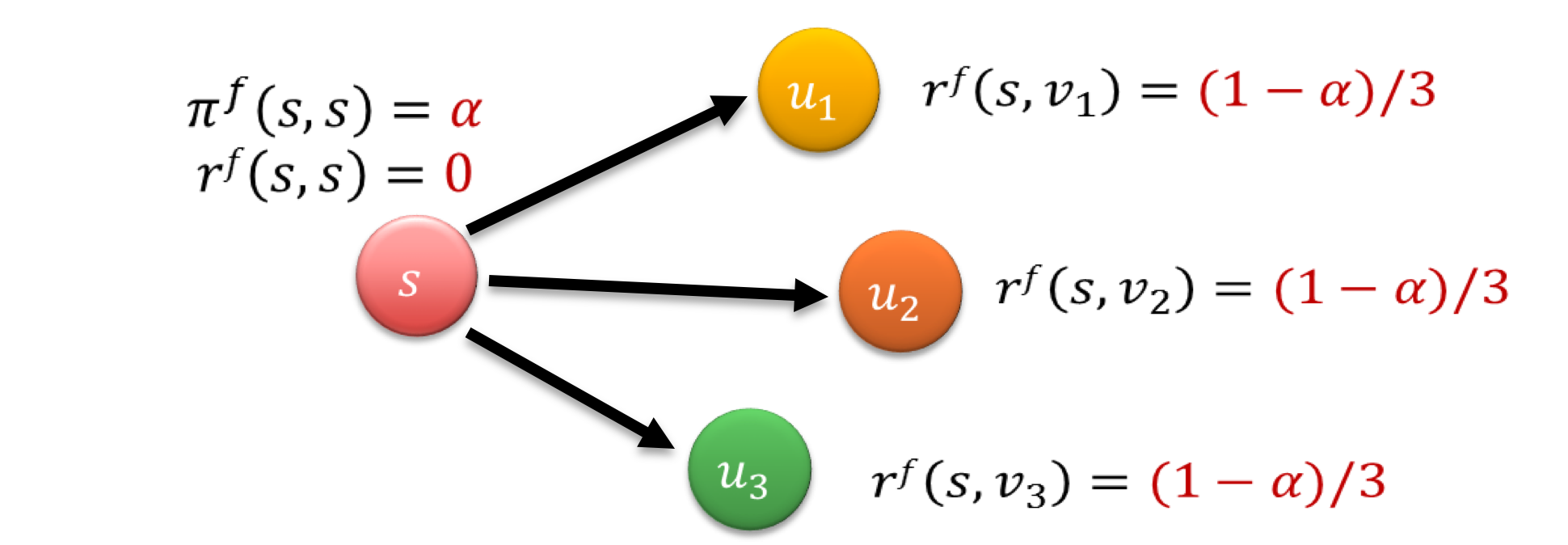
- 第一个节点没分配的时候
$\pi_f(s,s)=\alpha$,$r_f(s,s)=1-\alpha$ - 当分配到第二轮的时候
$\pi_f(s,s)=\alpha$,$r_f(s,s)=0$,$r_f(s,v_i)=(1-\alpha)/3$
则有
\begin{equation}\pi(s,t)=\pi_f(s,t)+\sum\limits_{v\in V}r_f(s,v)\dot{}\pi(v,t)\end{equation}
当$r_f(s,t)$很小的时候,运算就没必要再进行下去了
其时间复杂度为$O(\dfrac{1}{r_{max}})$
Backward Search
[WAW’07]
有Forward 很容易想到是不是有Backward
此时$\pi_b(v,t), r_b(v,t)$的定义和 Forward 基本一致
Reserve:$\pi_b(v,t)$从 v 出发,运行到 t, 且停在 tResidue:$r_b(v,t)$从 v 出发, 当前走到 t,不停
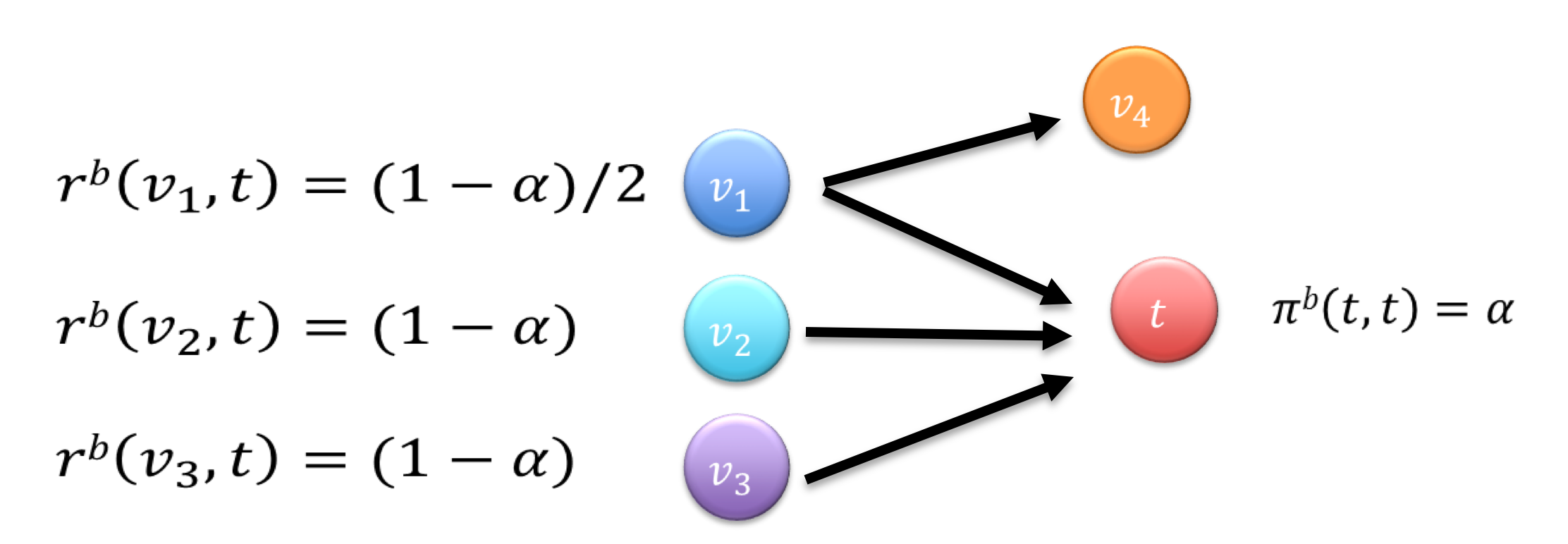
同样可以推出
\begin{equation}\pi(s,t)=\pi_b(s,t)+\sum\limits_{v\in V}r_b(v,t)\dot{}\pi(s,v)\end{equation}
当然可以吧 Forward Backward 结合在一起通过并行加快计算效率
FORA
[Wang et.al, KDD’17]
由上述可知
- Forward 精确解代价太高 可以较早的停止,但尾项不能保证近似解
- MC 可以保证得到的是近似解 但效率低下
就有学者把这两者结合在一起
在计算较大$\pi_f$时使用 Forward 当 Forward 进入停止迭代尾项的时候 使用 MC 进行计算 以提高精度
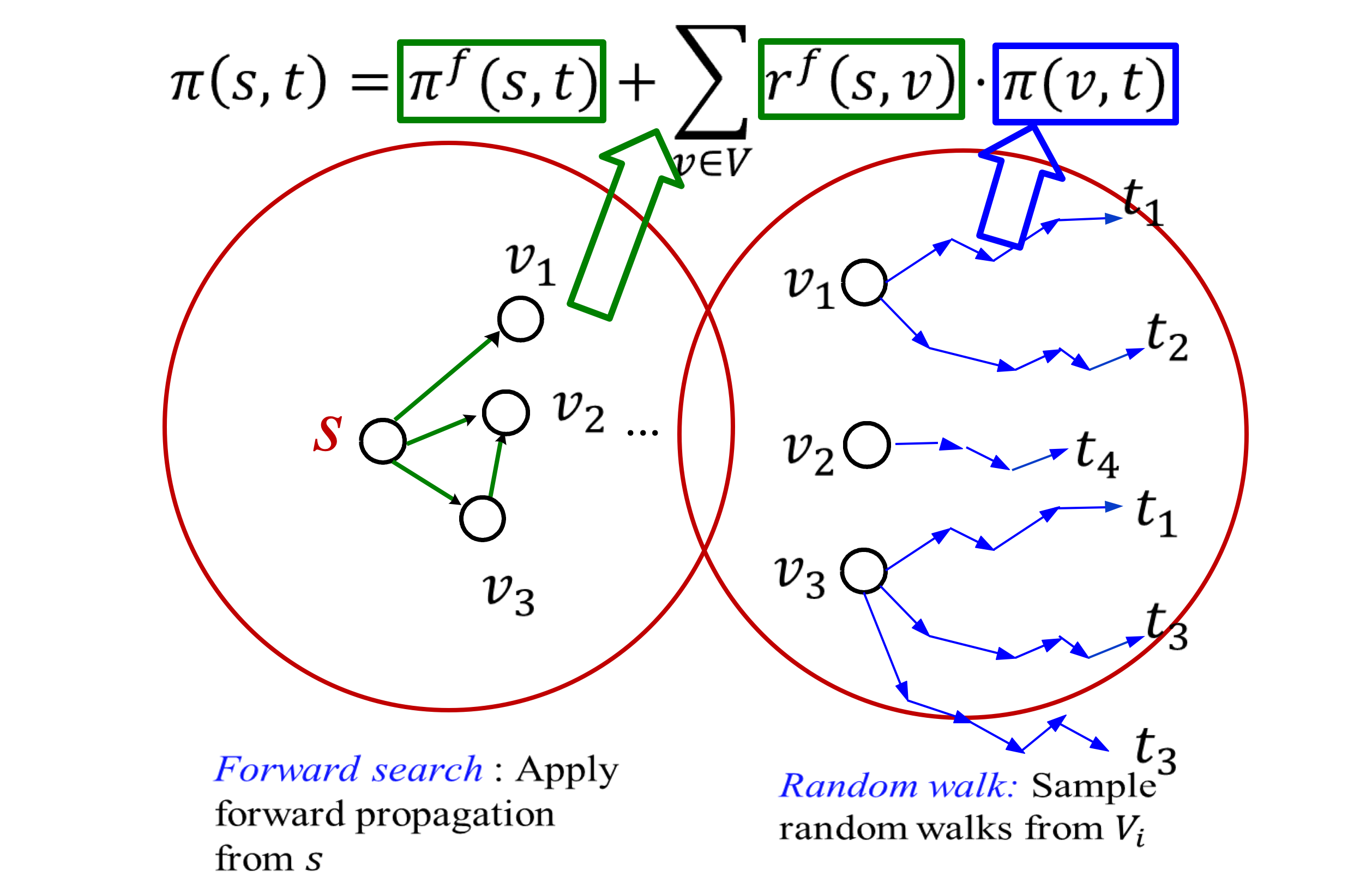
MC 那么精确 那为啥不一开始就用 MC 呢
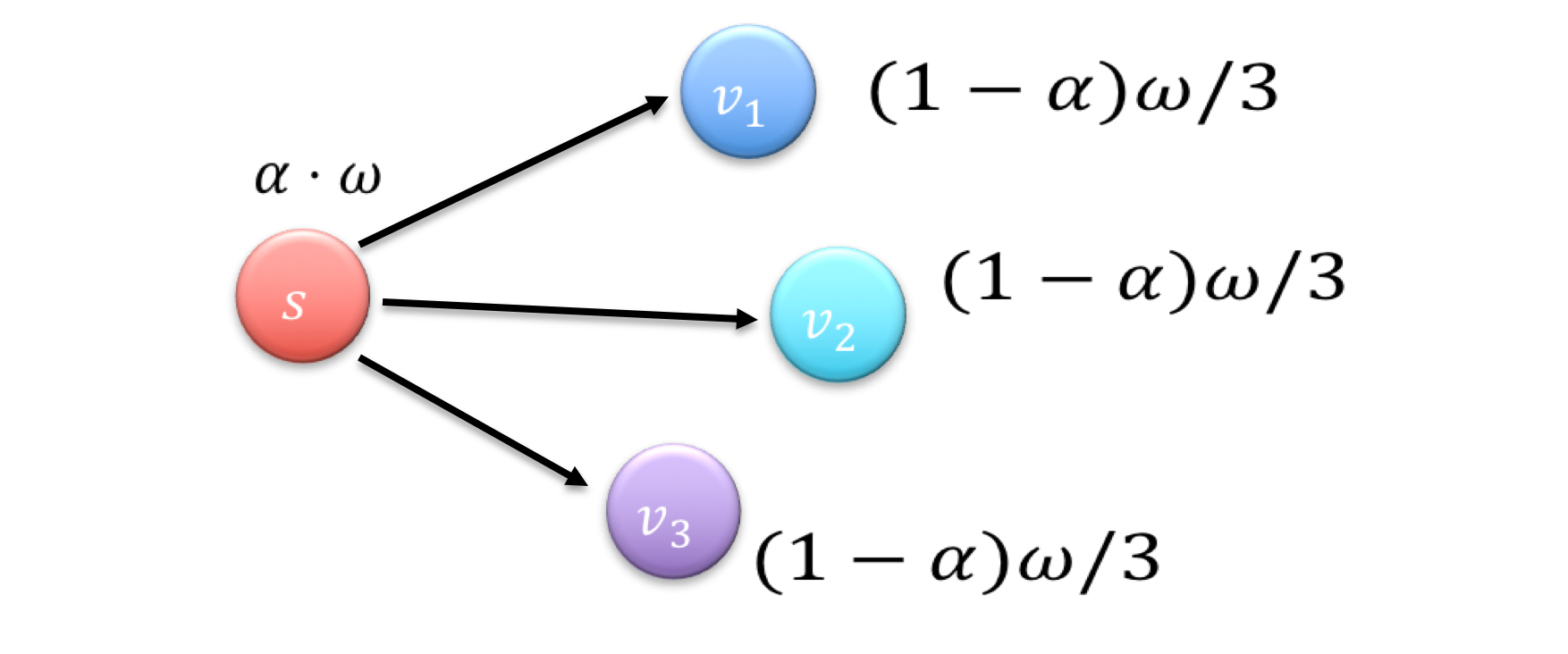
Forward 的 cost 大概在 MC 的$1-\alpha$倍左右, 举个栗子 还是 Forward 那张图
$Cost_f=(1-\alpha)w/\alpha+d_out$$Cost_M=w/\alpha$
这在数据量较大的情况下 差距还是比较可观的
Alias Method
现在插播一个算法
Alias Method 是一种大图中经常会用到的带权采样算法
一开始看见这个算法名字的时候觉得很眼熟
然后我同学提醒我~/.zshrc中有 (尴尬不失礼貌的微笑)
直译过来就是别名采样算法 (别问我采样怎么译出来的)
考虑一个问题:一个随机事件包含四种情况, 每种情况发生的概率分别为:
$\dfrac{1}{2}$,$\dfrac{1}{3}$,$\dfrac{1}{12}$,$\dfrac{1}{12}$, 问怎么产生符合这个概率的采样方法
一个很简单的思路就是产生一个$x\in[0,1]$的随机数 然后根据 x 检索到详情的具体情况, 这样就转变为搜索问题, 用 BST 可以达到$O(\log{n})$的复杂度
那有没有复杂度更好的算法呢?(我觉得$O(\log{n})$挺好的了 尴尬不失礼貌的微笑)
Naïve Alias Method
把所有情况排成一列 掷两次骰子 第一次决定列 第二次决定采样是否成功
如图,先掷一次骰子, 先确定是四种情况中的哪一种,如果是 A,则 100%采样 A; 如果是 B, 则$\dfrac{2}{3}$概率为 B,$\dfrac{1}{3}$概率重试
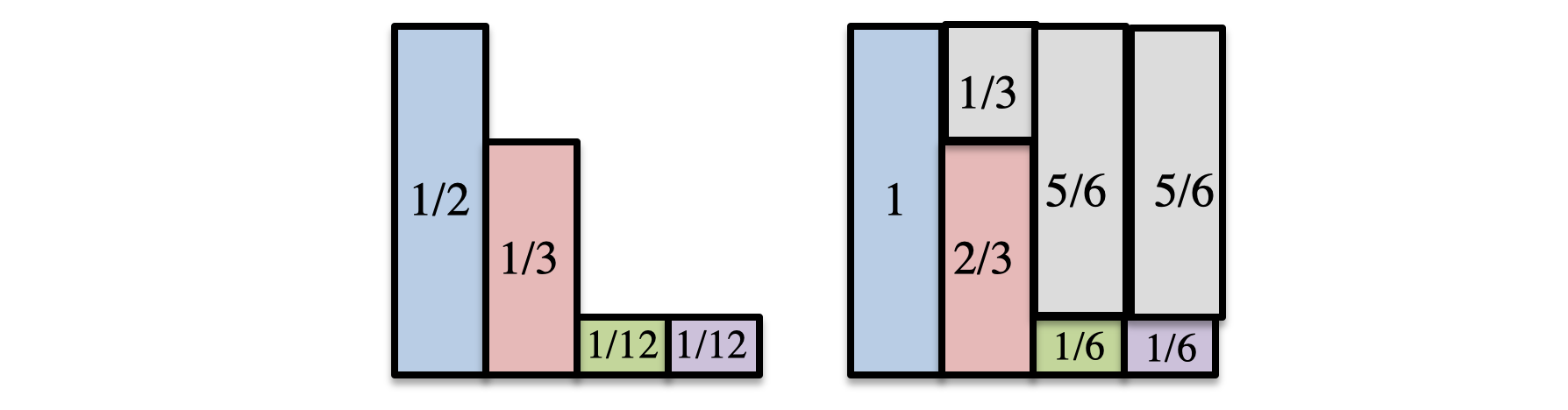
我们来考虑下复杂度, 最好的情况,一次就结束$O(1)$,不好的情况一直一直迭代下去,平均复杂度$O(n)$
Alias Method
回顾刚才的过程 可以发现 我们在重试的过程中可能会出现反复重试的情况 这样消耗太多 有没有什么办法能减少重试次数呢
如果我们能保证第二次掷骰子 🎲 的时候 不是当前类就是其他类 那么就不需要重试了吧
想法很好 究竟如何来实现呢 给出了下图的一个方法
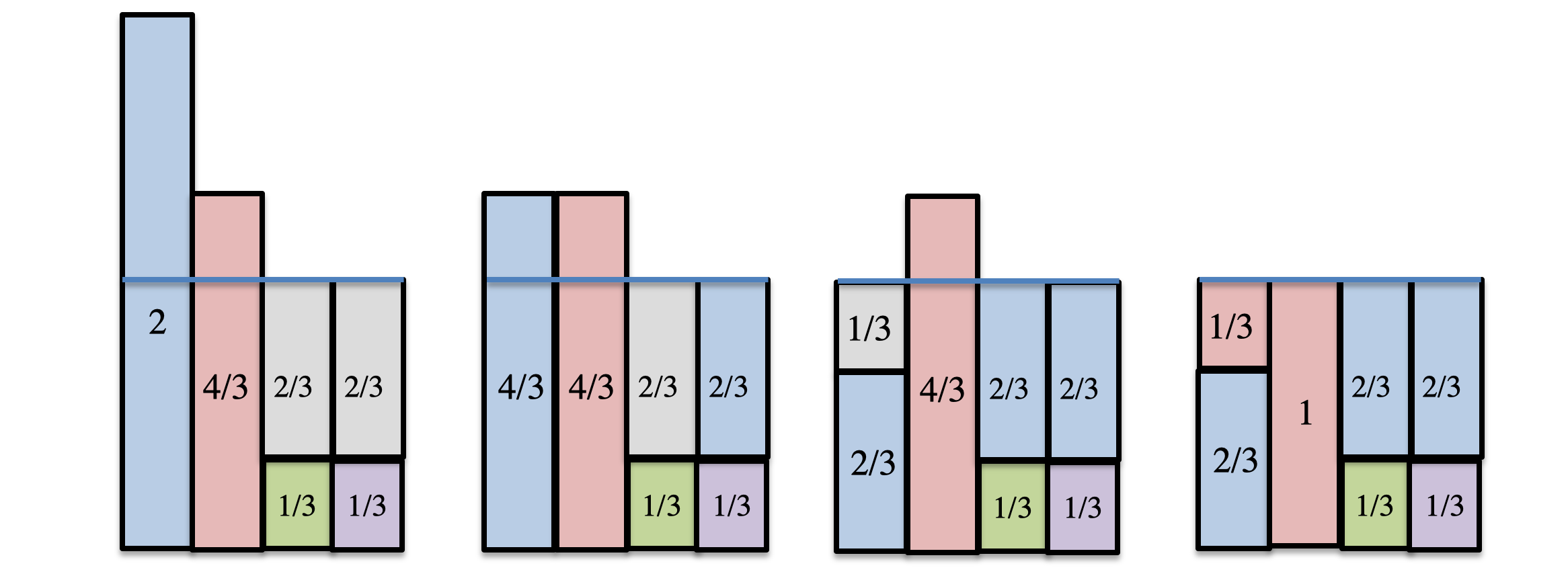
通过拼接来实现 保证第二次掷骰子的时候 不是 A 就是 B
但要注意这个拼接是有条件的:
- 满足一块中只能
最多两个拼接而成 - 第$i$块必须包含第
$i$块的一部分
当然就会产生一个疑问 到底 是不是都会存在这种拼接
事实上可以证明 Alias 拼接的存在性 具体参考 👉
为什么突然提到ALias采样算法?
回想一下 FORA 算法 第二步 MC 算法是在第一步达到停止条件之后的随机游动
在随机游走模拟初始化的时候就需要使用判别采样的类别
考虑下FORA的时间复杂度
MC: $O(\dfrac{n\ln{n}}{\epsilon^2})$
则 Radom Walk: $O(r_{sum}\dfrac{n\ln{n}}{\epsilon^2})=O(mr_{max}\dfrac{n\ln{n}}{\epsilon^2})$, 其中$r_{sum}=\sum\limits_{v\in V}r(s,v)\le \sum\limits_{v\in V}d_{out}(v)r_{max}=mr_{max}$
则 Total: $O(\dfrac{1}{r_{max}}+mr_{max}\dfrac{n\ln{n}}{\epsilon^2})$
令$r_{max}=\epsilon \sqrt{\dfrac{1}{nm\ln{n}}}$
则: $O(Total)=O(\dfrac{1}{\epsilon}\sqrt{mn\ln{n}})$
Top-K single source PPR
事实上 在很场景下 我们并不关心所有的 PPR 值
大部分时候只对 Top-K 感兴趣
如何精准的估计前 K 个 或者说 第 K 个 PPR 值 成了关键问题
解决 Top-K 的一个简单的想法就是利用迭代
- 给定初始值
$\delta = \dfrac{1}{k}$ - Run FORA
- Test solution
- 通过上下限来评估 PPR 值
- 如果没满足精度,则
$\delta /= 2$, 重复第二步 - 如果满足精度则输出
Multi-armed Bandit
然后再插播一个问题?(还是算法) 傻傻分不清🙉
假如说你进到一个赌场 有 n 台老虎机 🎰 看起来这 n 台老虎机没啥区别 但事实上 每台老虎机都有自己的概率分布 那么如何制定策略尝试 从而在最小的代价下获得最大的利益
这就是多臂老虎机MAB问题

其实这是一个在 Reinforcement learning, RL 领域很火的问题
也拥有极强的应用场景
推荐系统 中 EE(Exploit-Explore)和冷启动是两个经典的问题
EE直译就是利用与探索,到底是应该利用目前为数不多的数据进行分析 还是应该再做探索拿到很多的信息
冷启动,主要针对的是用户第一次进入系统,在对用户一无所知的情况下,如何更有效的进行推荐
解决这两个问题的一个有效途径就是MAB算法
A/B test
最简单的一种思路就是每台老虎机 🎰 尝试 n 次 记录回报值 哪台老虎机平均回报最大 就选哪台
A/B test 的核心就是控制变量
- 每台老虎机在相同条件下尝试相同的次数 n
- 然后根据这
$n\times m$的结果,对老虎机收益进行估计
但很显然这样的算法 要达到一定精准度 需要较大的代价
$\epsilon$-Greedy
直译就是贪婪算法 (很贪婪了)
这个算法有点像前面说的 Naïve Alias Method, 通过随机结果估计样本情况
- 指定一个
$\epsilon \in (0, 1)$ - 每轮结束的时候,以概率
$\epsilon$决定探索, 在所有老虎机中选一个作为下一个尝试项 - 以概率
$1-\epsilon$决定利用, 选择当前获取的样本中最好的老虎机作为下一个尝试项
这是一个 online 过程,随着尝试次数 n 的增大,所得到的结果就越接近真实值
且随着$\epsilon$值的增大,收敛速度越快 (越激进越有可能发现真理 所以同学们 要保持对这个世界的怀疑)
但$\epsilon$-Greedy 忽略了可能已经表征出来的特征 从始至终的都是随机筛选 可能会花费过多的时间才能收敛
当然$\epsilon$-Greedy 也有很多变种
- 比如说一开始尝试概率高 之后概率慢慢减小
- 通过预筛选 先框定小范围 再进行
$\epsilon$-Greedy
SoftMax
大致思路就是 根据现有的信息进行估计 选择最可能的情况
- 根据之前的情况计算每一台老虎机的
$p_k=\dfrac{e^{\bar\mu_k/k}}{\sum e^{\bar\mu_k/k}}$值 - 选择
$p_k$值最大的作为下一阶段选择的老虎机
好像和前面的没啥区别 都是根据现有的信息 来估计分布
实际上 SoftMax 的最大特点就是通过一个变量 T,Temperature 来控制估计范围的力度
T-温度,直观的感受,随着时间的增大,T 随之减小 那么在分母的 T 导致现有的样本权值变高 越来越占主导地位
另外 SoftMax 也有一些变体,比如说$p_k=(1-\gamma)\dfrac{w_k(t)}{\sum \limits_{j=1}^K w_j(t)}+\dfrac{\gamma}{K}$, 其中$w_j(t+1)=w_j(t)exp(\gamma \dfrac{r_j(t)}{p_j(t)K})$
UCB
虽然SoftMax已经有一种感觉 越多估计越可用 但它没有考虑到置信区间的问题 UCB 则从置信区间出发
UCB = Upper Confidence Bound
- 先对每一个老虎机都进行一次测试
- 计算
$p_k=\bar{\mu}_k(t-1)+\sqrt{\dfrac{2\ln{t-1}}{T_{j,t-1}}}$, 其中$T_{j,t-1}$为截止到第 t 轮 j 这台老虎机试验次数 - 选择
$p_k$值最大的作为下一阶段选择的老虎机
和 SoftMax 相比 只是$p_k$计算方法略有区别 然后还多了一次预操作处理
仔细观察$p_k$式子,其中包含了试验次数
随着试验次数的增大后面那项值越小,均值占得比重越大; 而试验次数较小的时候,后项值较大,均值占比较小
从而减少 因为采样次数较少造成的错误估计
本质上 后一项是均值的标准差
那么 为何叫做上置信区间算法呢?其实这个式子是从置信区间推出来的
根据上置信区间公式可得$P(\bar{\mu}\ge\epsilon)\le exp(-n\epsilon^2/2)$, 令右侧=$\delta$, 则有$P(\bar{\mu}\ge\sqrt{\dfrac{2}{n}\log{\dfrac{1}{\delta})}}\le \delta$
则其 均值估计就为$\bar{\mu}_i(t-1)+\sqrt{\dfrac{2}{T_i(t-1)}\log{\dfrac{1}{\delta}}}$
当然 UCB 还有很多改进版本 在这就提出一个最朴素的思想
Thompson sampling
之前 UCB 是从置信度的角度出发考虑问题
而Thompson sampling则是站在贝叶斯的角度 通过维护一个 beta 概率分布用先验估计后验
- 对每台老虎机维护一个 tuple(winner, lose), 里面存放着历史成功、失败数,其中 winner,lose 为 beta 分布的参数
- 每轮,每台老虎机的 beta 分布随机产生一个值
$p_k$ - 选择
$p_k$值最大的作为下一阶段选择的老虎机
相对而言 Thompson sampling 的计算量会更小
实际使用效果也和 UCB 不相上下 基本上是目前使用比较多的一个算法
Top-K arm indentification
刚才我们分析都是选择收益最大的老虎机
实际上我们的需求不一定有那么强 可能只需要知道一个 Top-K 的集合就行了
比如说我们这个问题 只需要知道 Top-K 的 PPR 值
Naïve Solution
选择实验结果的第 i 大老虎机$\epsilon$范围内的老虎机
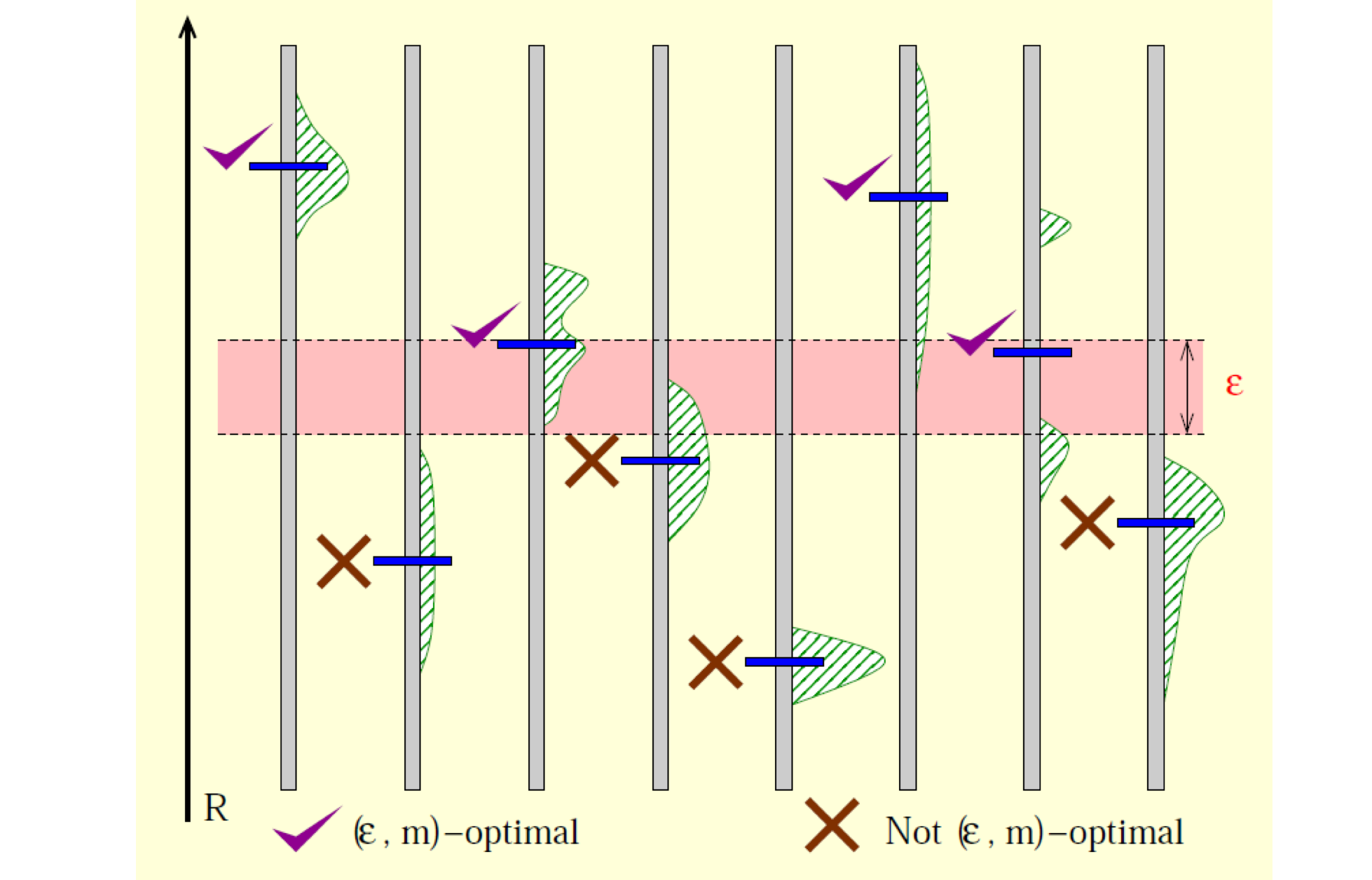
MC solution
好 我们回到前面讲的Top-K single source PPR
想必 很多人 已经忘记我们这片 blog 的主题了 (连我自己也觉得我就是在讲 🎰)
好跟我念 PPAPPPAPPPR 好 回到我们的 Top-K PPR
利用Chernoff bound估计所有点的 UB LB 且所有点的$UB-LB$均相等
则带入 Top-K single source PPR 根据停止条件 UB LB 进行 MC 迭代
然后根据前面说的banbit算法估计前 k 个 PPR
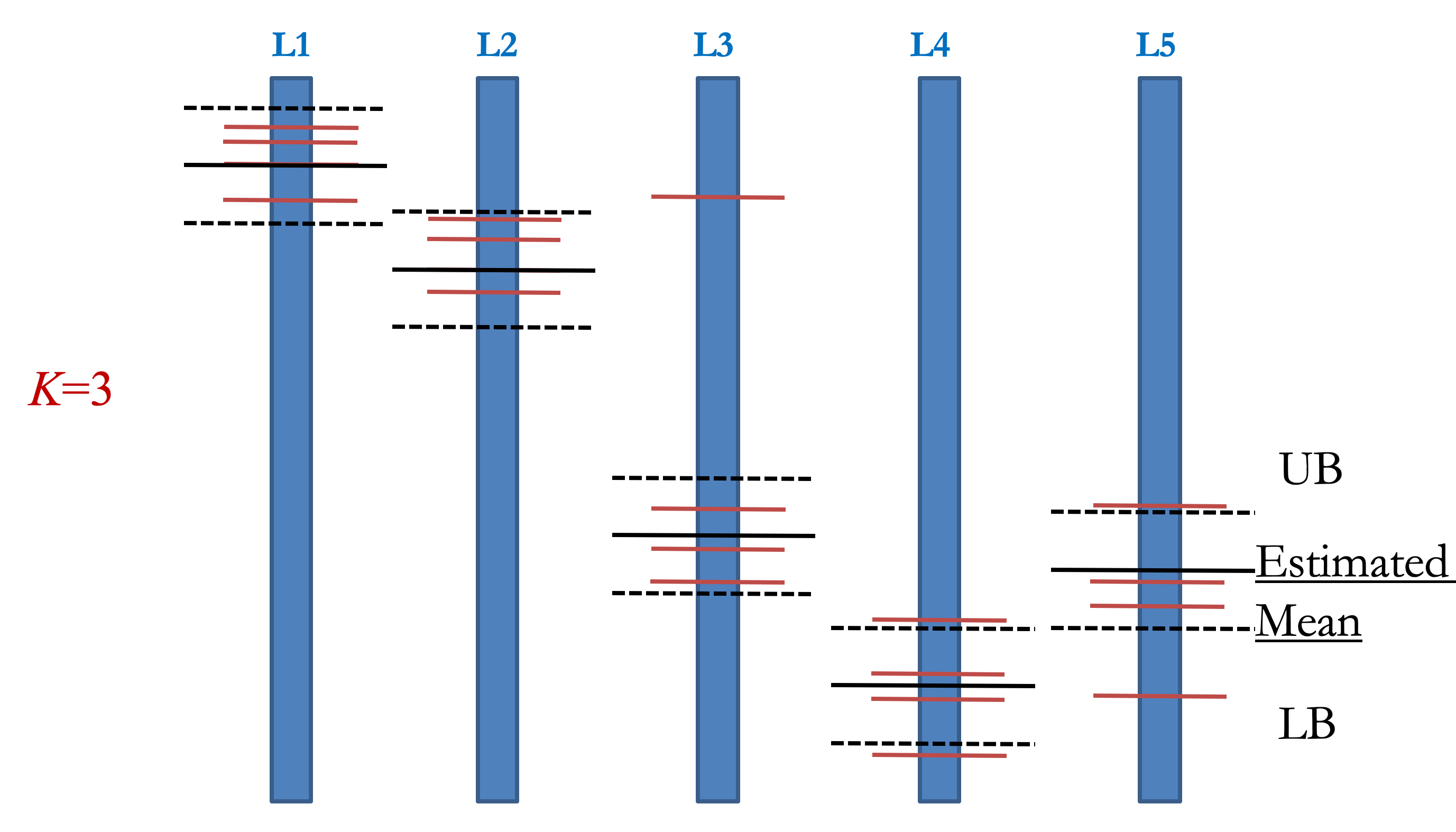
TopPPR algorithm
[Wei et.al., SIGMOD 18]
MC 的实际精度表现的比较低,于是又学者考虑把 FORA 和 Backward 结合在一起
利用 Backward search 改善精度,得到了 TopPPR algorithm
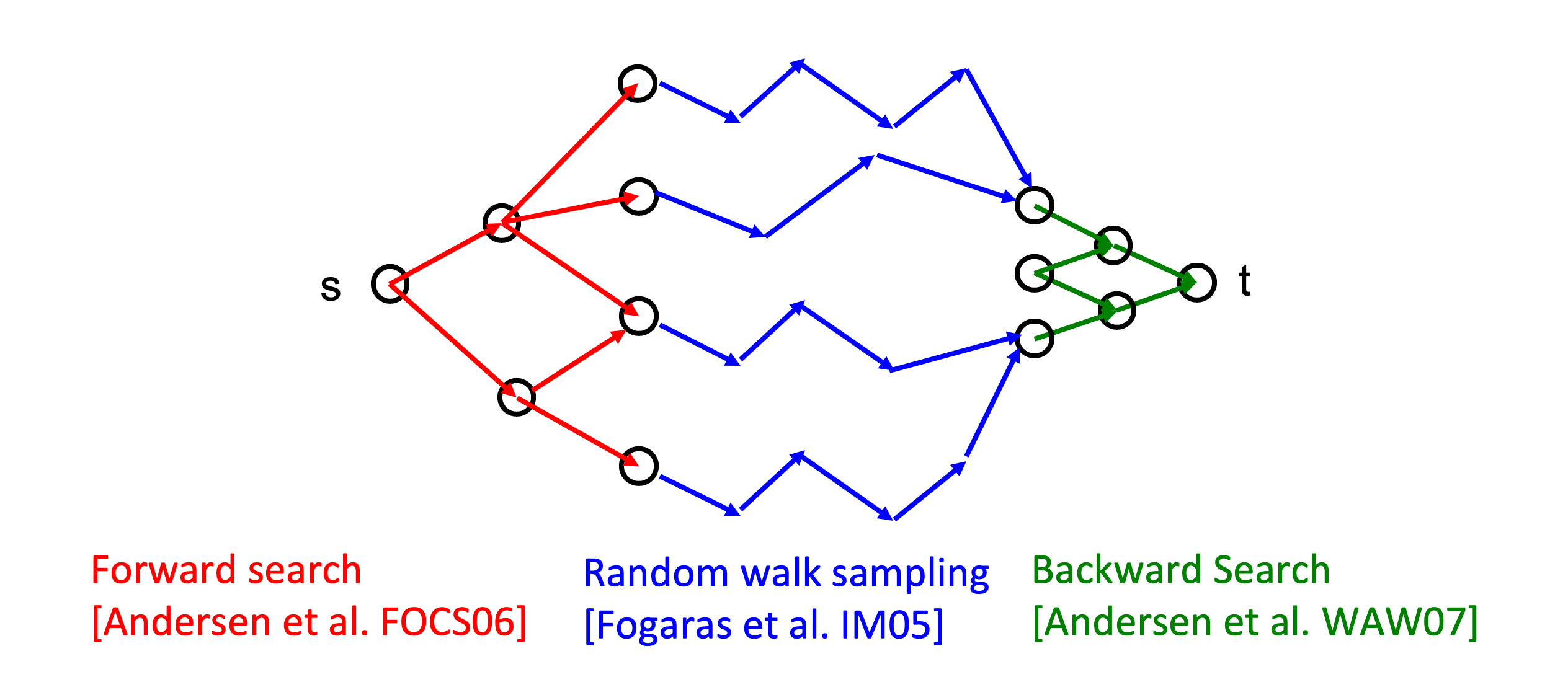
\begin{equation}\pi(s,t)=\pi_f(s,t)+\sum\limits_{u\in V}r_f(s,u)\pi_b(u,t)+\sum\limits_{u,v\in V}r_f(s,u)\pi(u,v)r_b(v,t)\end{equation}
但问题是 Backward 必须知道目标点 对 Top-K 而言 就是需要给出一个候选集
于是我们大致把候选集分为三个集合 一定是Top-K的可能是不可能是
反复迭代 通过Empirical Bernstein不等式计算置信区间
注意在迭代过程中 每个点的采样次数不同 UB LB 的差也不同
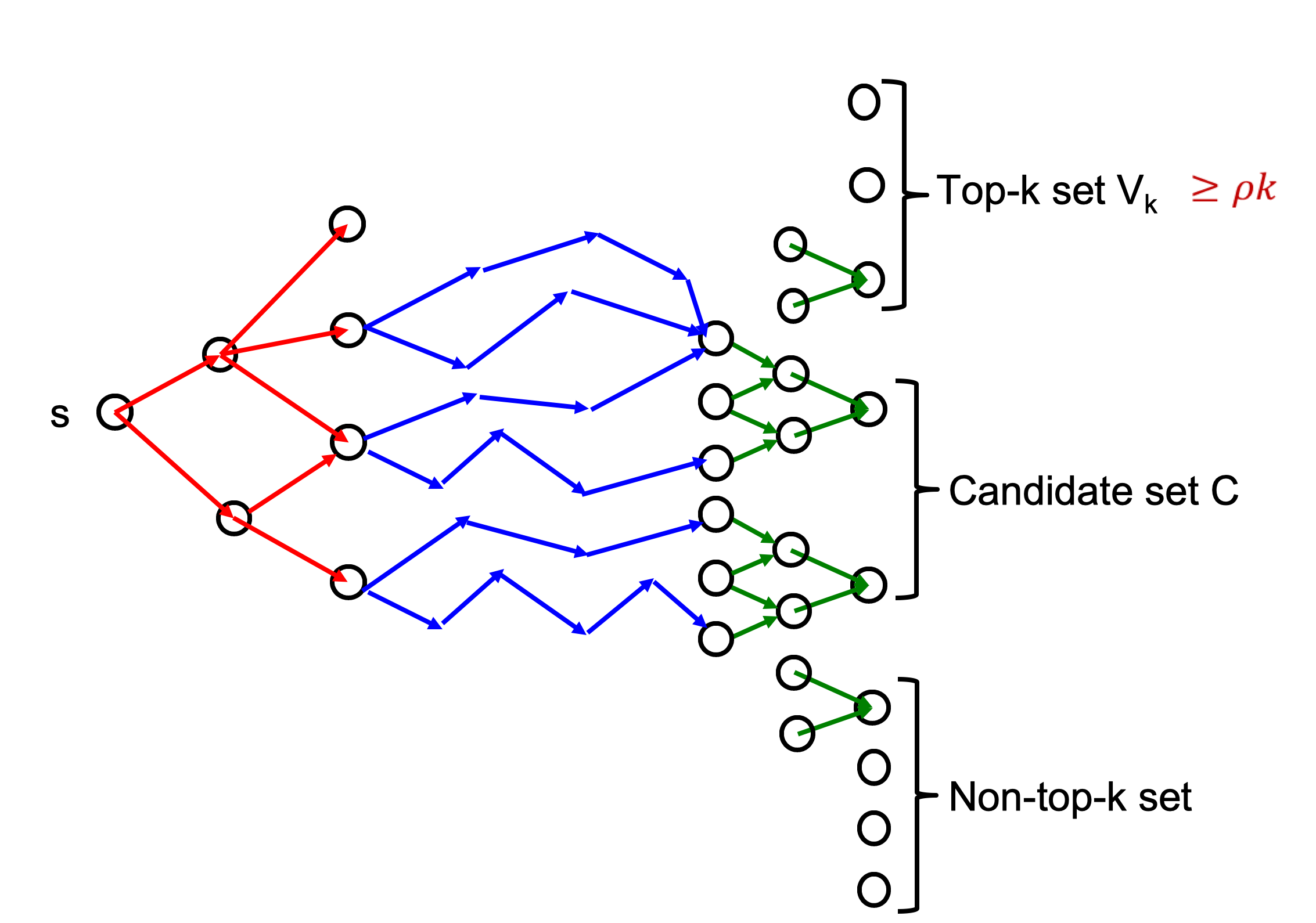
回顾下刚才的 UB-LB 算法 可以发现在第 k 大 PPR 附近的点 很容易被误采样进样本中
好 到这里大致把 PPR 的图搜索算法讲完了
另外 PPR 的矩阵计算 最近几年也得到不错的成果
虽然目前工业界主流采用图搜索算法 (毕竟复杂度$1-\alpha$倍)
Reference
- The PageRank citation ranking: Bringing order to the web
- Towards scaling fully personalized pagerank: Algorithms, lower bounds, and experiments
- Local graph partitioning using pagerank vectors
- Local computation of PageRank contributions
- FORA: simple and effective approximate single-source personalized pagerank
- Topppr: top-k personalized pagerank queries with precision guarantees on large graphs
- Chernoff bound
- Darts, Dice, and Coins: Sampling from a Discrete Distribution
- Vermorel, Joannes, and Mehryar Mohri. "Multi-armed bandit algorithms and empirical evaluation." European conference on machine learning. Springer, Berlin, Heidelberg, 2005.
- The Upper Confidence Bound Algorithm