Frequent Pattern
作为 Data mining 的第一篇 先来讲讲频繁模式
频繁模式是推荐算法的基础
主要解决的是从一堆数据中挖掘出频繁的组合模式
举个简单的例子
可能买了 Mac 的人,过几天会去买贴膜 可能买考研英语书的人,过几天会去买考研数学书
如何在大量数据中找到可能相关的几个问题,称之为 Frequent Pattern
频繁程度通过支持度、置信度两个参数来衡量
A->B support: 即模式 A, B 出现频率
A->B configure: 即模式 A 发生情况下 B 发生的概率
Item Sets
Item Sets 指的是假设不考虑数据之间的顺序
Apriori
我们可以得出
- 如果一个集合是频繁集,那么它的所有子集都是频繁集
- 如果一个集合不是频繁集,那么它的所有超集都不会是频繁集
根据这一点,Agrawal & Srikant 在 94 年提出了著名的 Apriori 算法
主要思想就是从大小 1 开始遍历可能频繁集 k 当满足 V所有集合子集都在之前计算过的频繁集 k 中,且出现次数满足频繁要求 则 V 为 k+1 频繁集
伪代码:
Ck: Candidate itemset of size k
Lk : Frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk !=; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1
that are contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
2
3
4
5
6
7
8
9
10
11
12
举个简单的例子
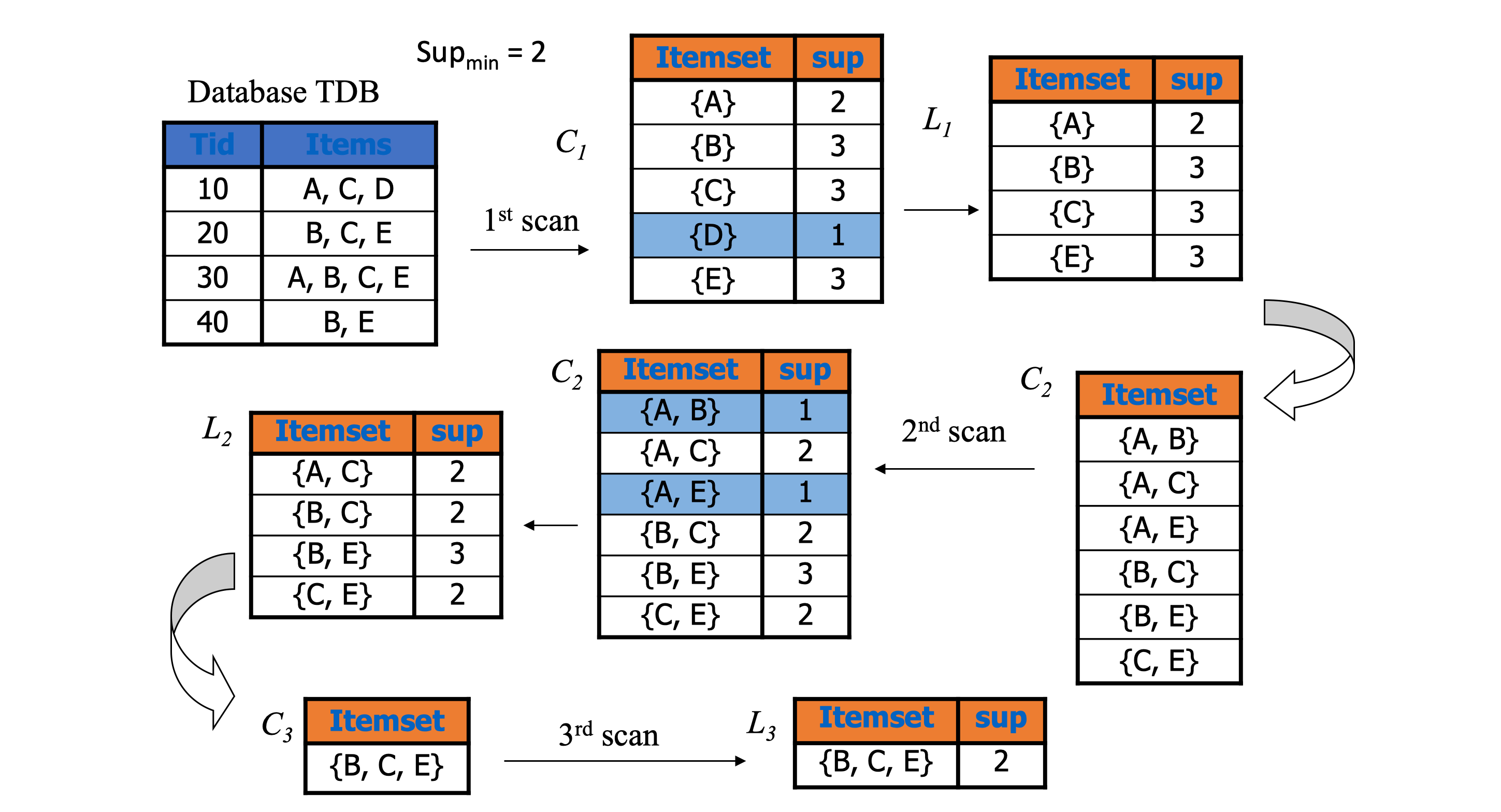
但 Apriori 也有一些缺点
- 多次读取数据,复杂度高
- n 较大,可能的取值较多
Apriori 也有一系列改进算法,比如说用 hash 存储可能的取值,做剪枝等等
FP-tree
仔细想一下上述算法的实现过程
一层层扩展,从大小为 1 开始,到 2,再到 k,到 k+1
是不是很像 BFS
那么我们不免想是不是会有类似 DFS 的算法
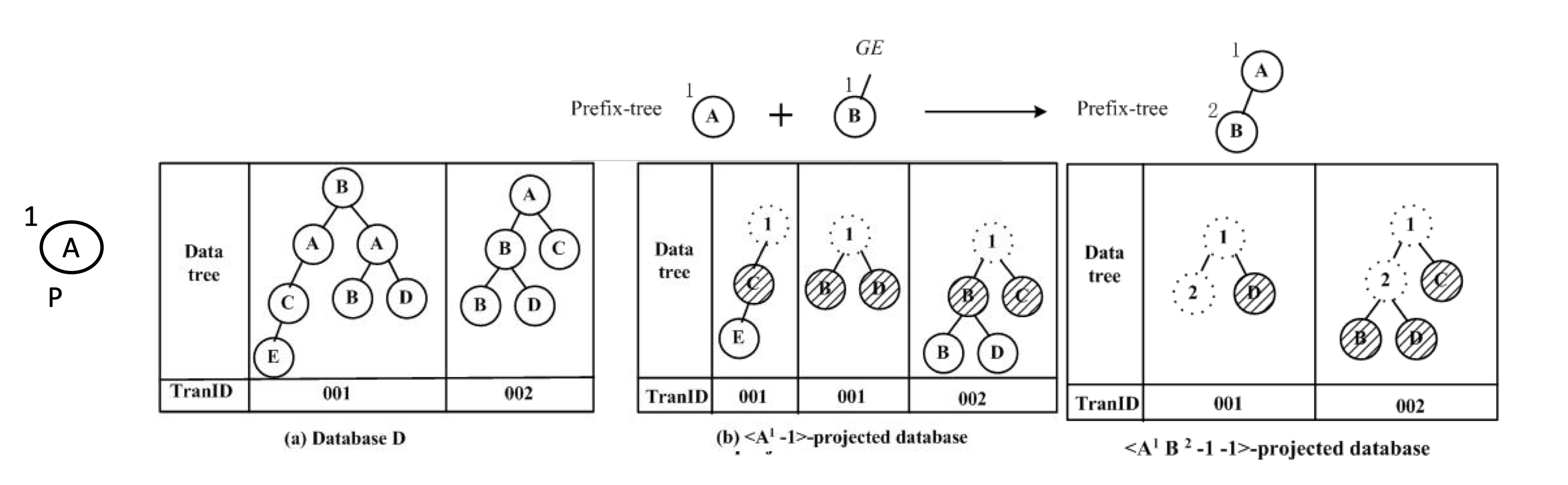
Jiawei Han, Jian Pei 在 2000 年提出 FP-tree 算法
通过构造前缀树来实现类似深度搜索的算法
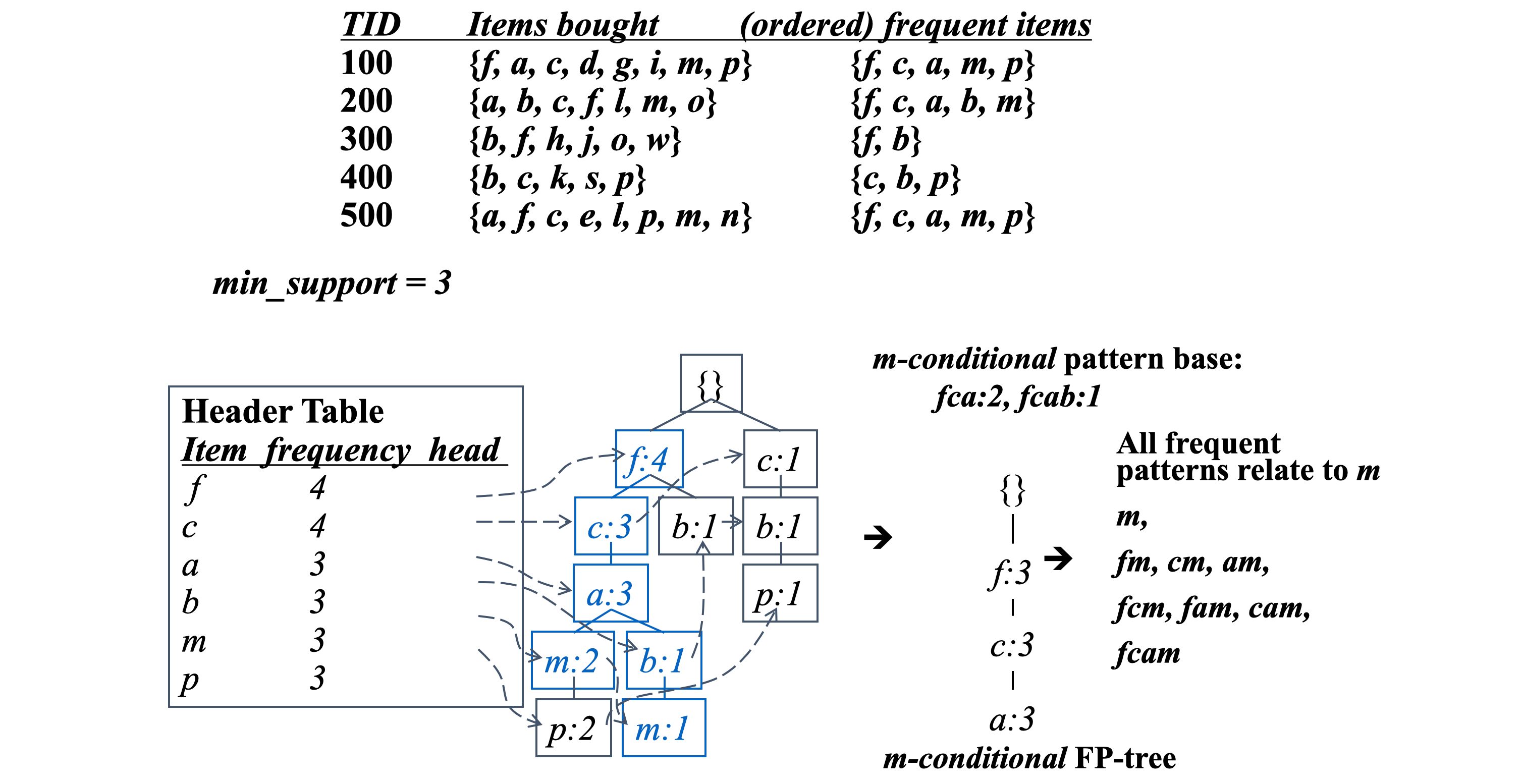
先把所有集合按字母出现频次逆序排列,筛选出现频次小于 min_support 值的项
然后找所有 DB 中所有满足当前前缀 abc 的项,DB|abc
依次遍历
算法通过前缀树 Trie 实现
举个简单的例子
Sequences
刚才说到的 Item Sets 中间的数据为无序的,但实际中,很多频繁集是在特定顺序下才成立的
Sequence 主要研究的就是带有顺序的情况, 把每次操作的项放在集合 Si 中,集合 S1, S2, ...,Sn 组成序列集
同样求在最低支持度下所有的频繁集
GSP
Join Phase 在 96 年提出类似 Apriori 的算法 GSP
和 Apriori 唯一的差别就是如何计算子集
现在 GSP 中的集合 S 为集合的集合
定义 S 的子集 C 满足
- Ci 为 Si 的非空子集, 当 i∈[2, n-1]
- Ci 为 Si 的子集, 当 i==1 | i==n
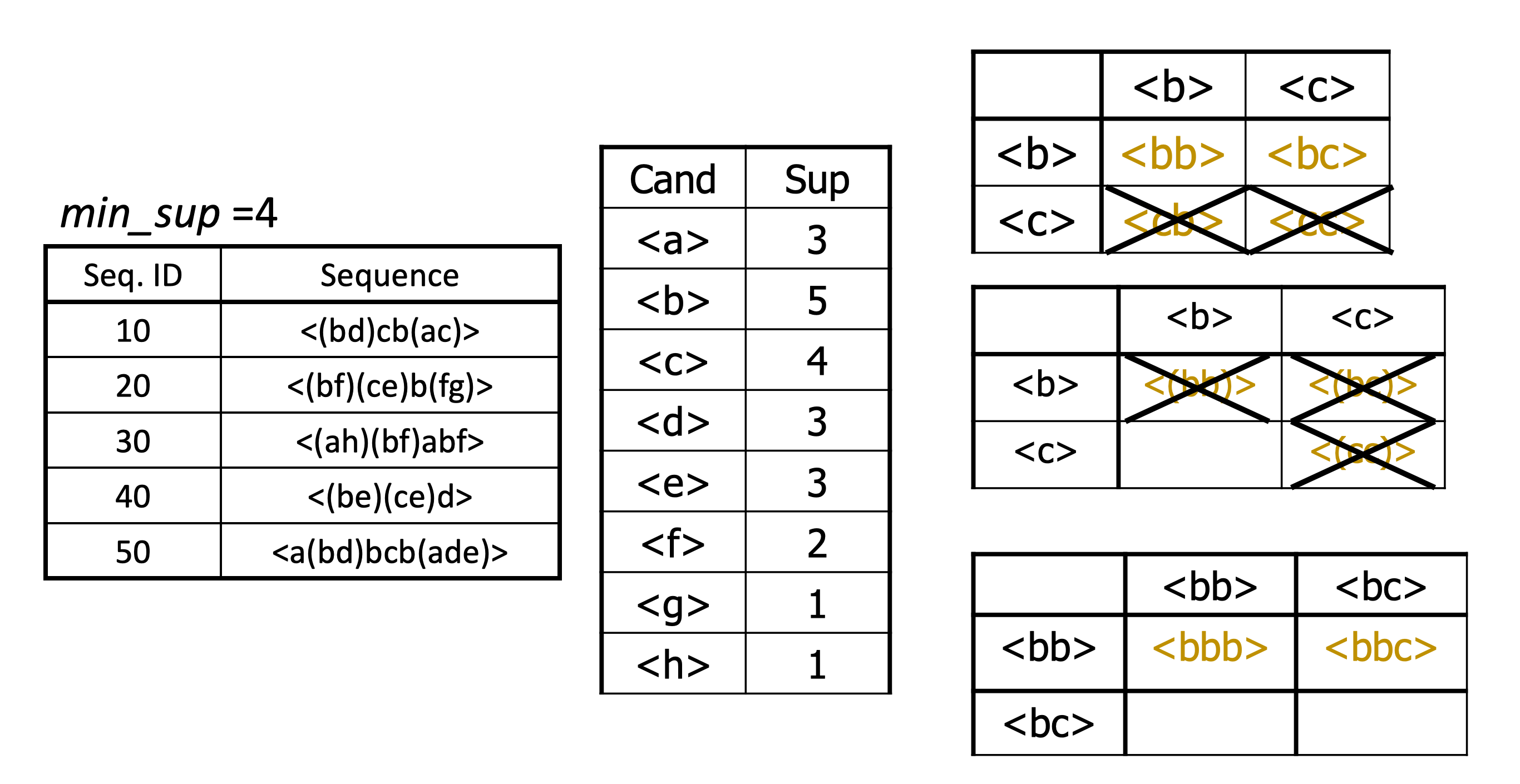
PrefixSpan
PrefixSpan 全称为 Prefix-Projected Pattern Growth
前缀投影就是后缀 Suffix,那么什么是前缀和后缀呢
定义 <a(abc)(ac)d(cf)>的前缀、后缀为
| Prefix | Suffix |
|---|---|
<a> | <(abc)(ac)d(cf)> |
<aa> | <(_bc)(ac)d(cf)> |
<ab> | <(_c)(ac)d(cf)> |
PrefixSpan 的思路就是
从 a 开始遍历所有满足 min_support 的前缀
然后对后缀检查是否满足 min_support,若所有项都满足,则保留满足项
然后依次合并前缀项,递归遍历
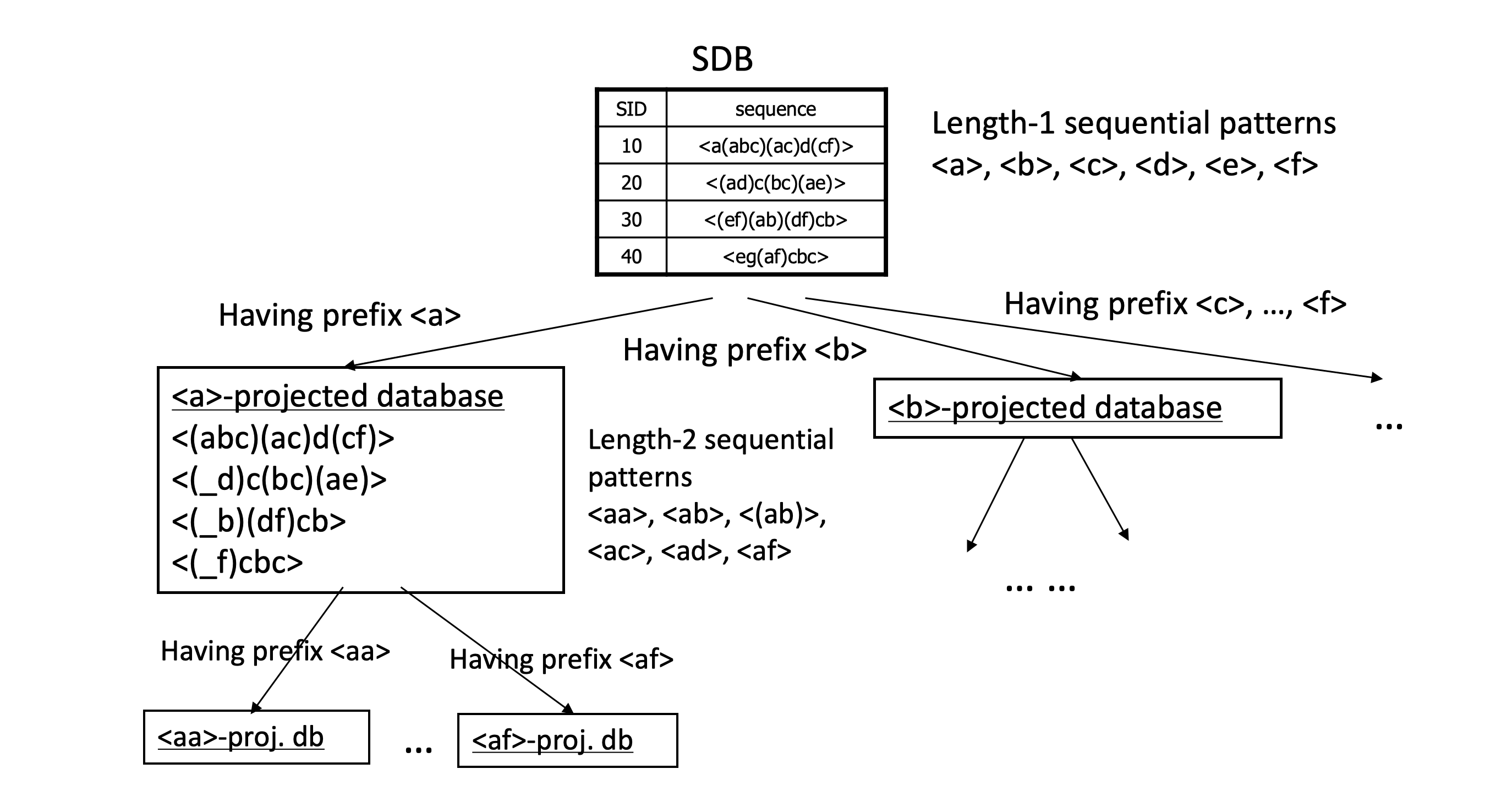
Tree patterns
当前面的集合推广到数结构
解决的主要是类似于网站链接的场景
范围编码
思考这么一个问题
有一颗树 如何判断是否是节点 A 是不是节点 B 的祖先
一般一点的办法就是以 A 为 root 节点,向下遍历,如果遍历到 B 则说明 A 是 B 的祖先
但这样很显然当树的规模比较小的时候还可以,但一旦树结构复杂时,就会接近 O(n), 尤其是需要多次查找时
有人就想出一个 O(1)的算法
先 先序遍历 一次树,第一次遍历到该节点时记录时间为 Tleft, 再次到节点记为 Tright
用区间[Tleft, Tright]表示该树的祖孙关系
当 A 节点的区间为 Ka,B 节点的区间为 Kb 时
- 若 Kb 属于 Ka,则 A 为 B 的祖先
- 若 Kb∩Ka=∅,则 A, B 为广义兄弟
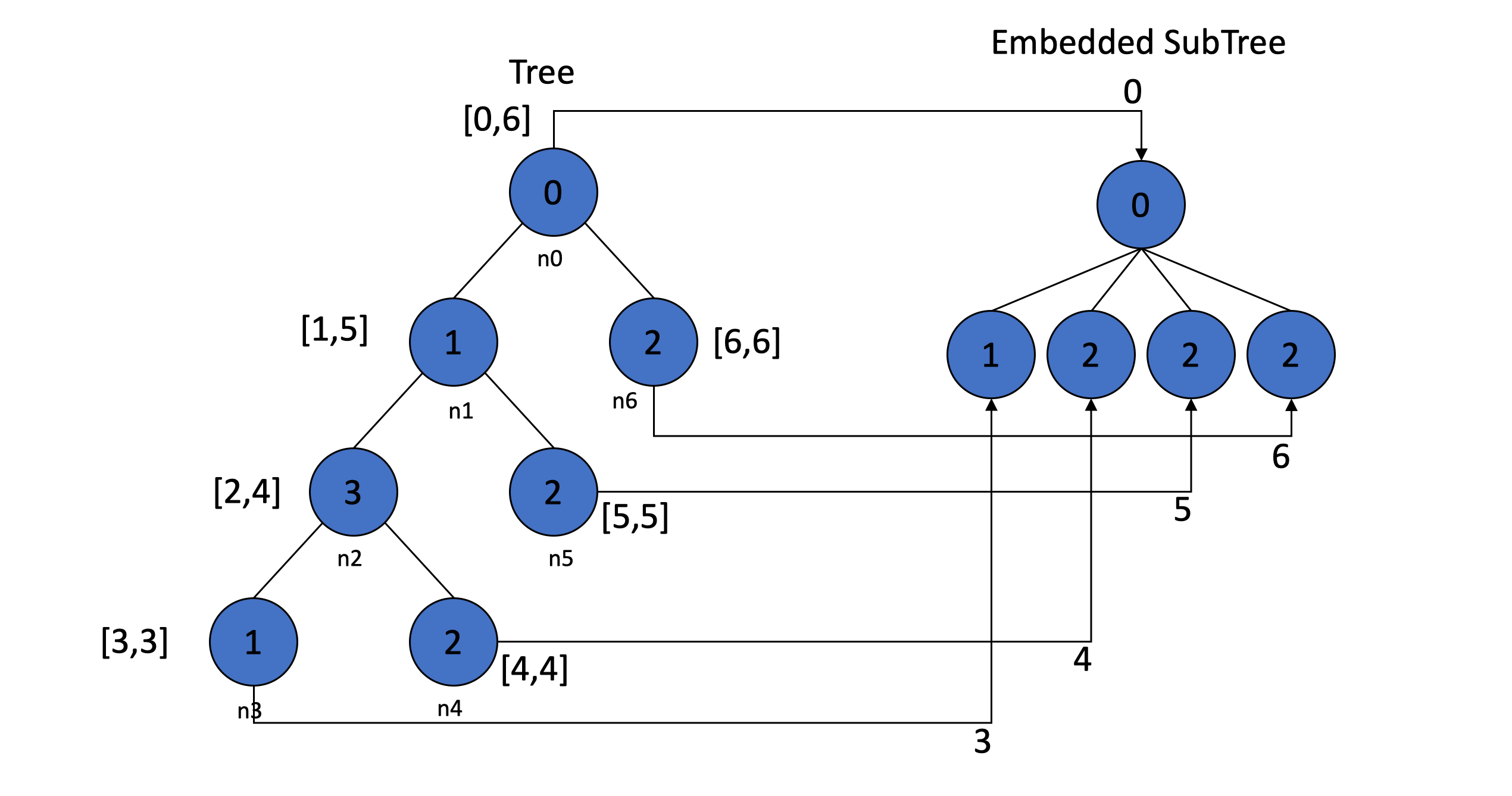
只要遍历一次建立区间索引之后,再次确认节点间的祖孙关系只需 O(1)
String Representation of Trees
利用 string 表示一棵二叉树
按先序遍历二叉树
- 如果第一次遍历到该节点则输出节点值
- 如果到达边界条件,跳出递归则输出-1
那么可以利用输出的节点值唯一的表示一棵二叉树
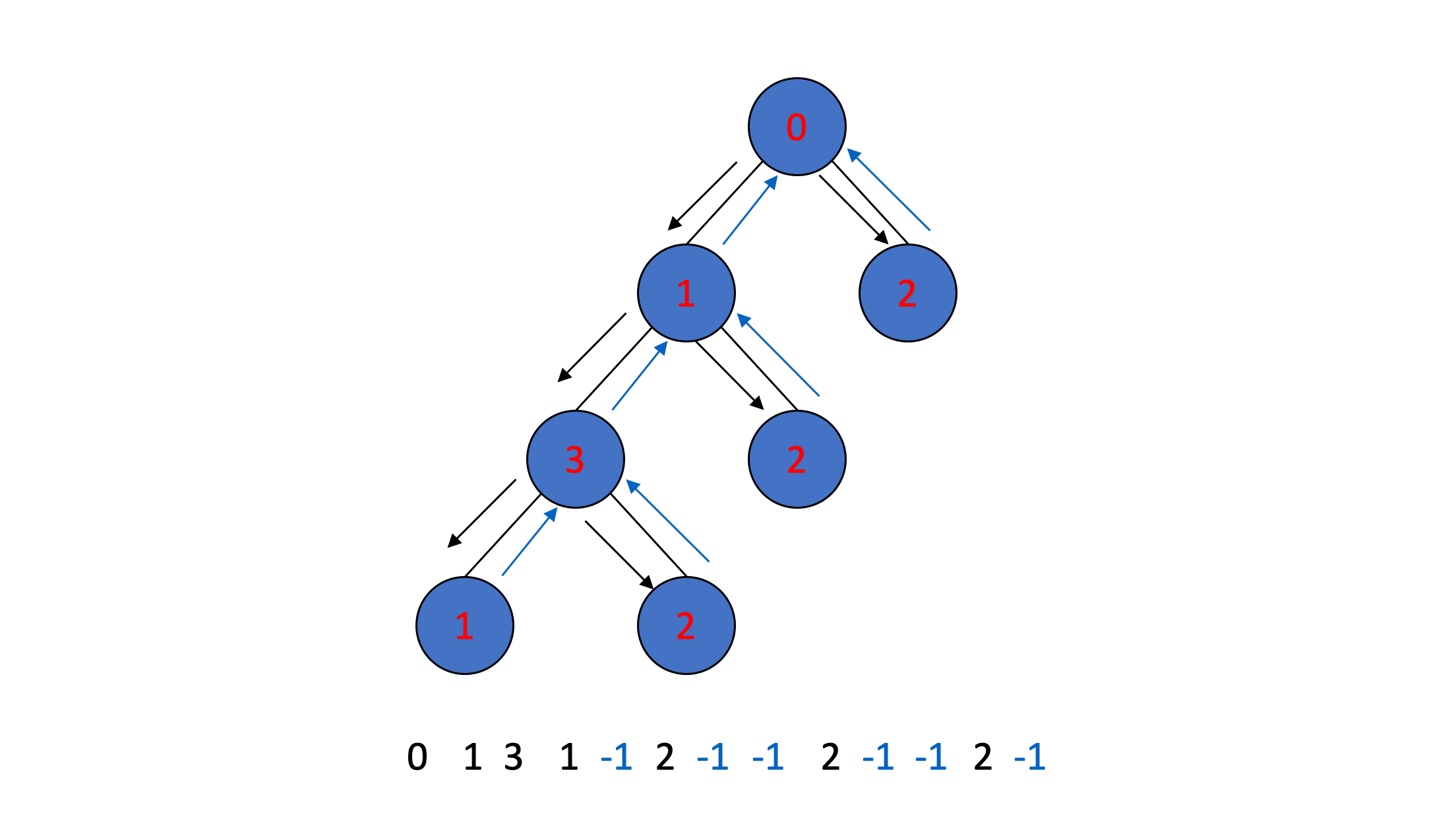
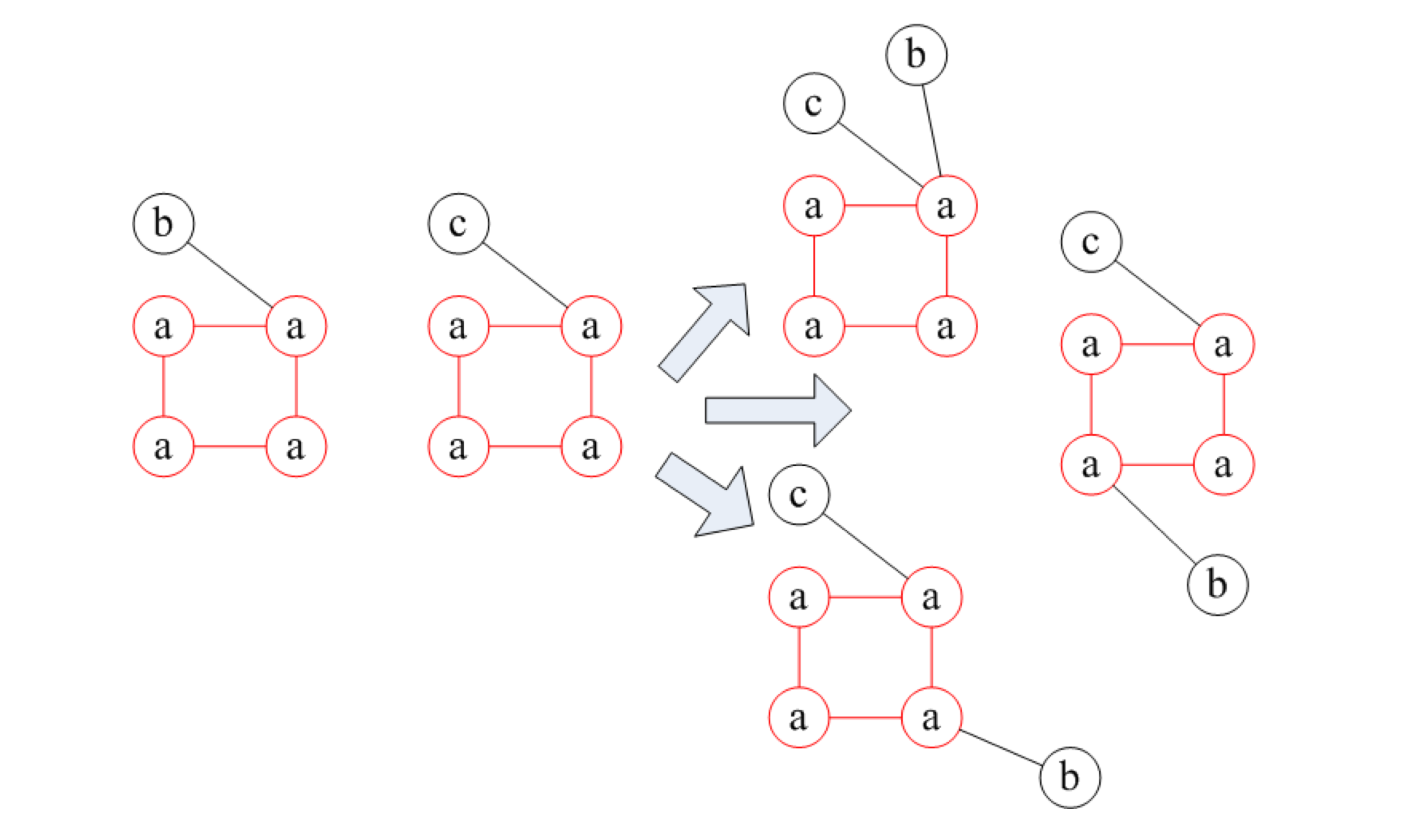
Equivalence Classes
因为前面用 String 来表示一棵树
如果两棵树具有相同的前缀,我们就称这两棵树为 Equivalence Classes
举个例子, 右侧的几棵树都有相同的前缀 3 4 2 -1
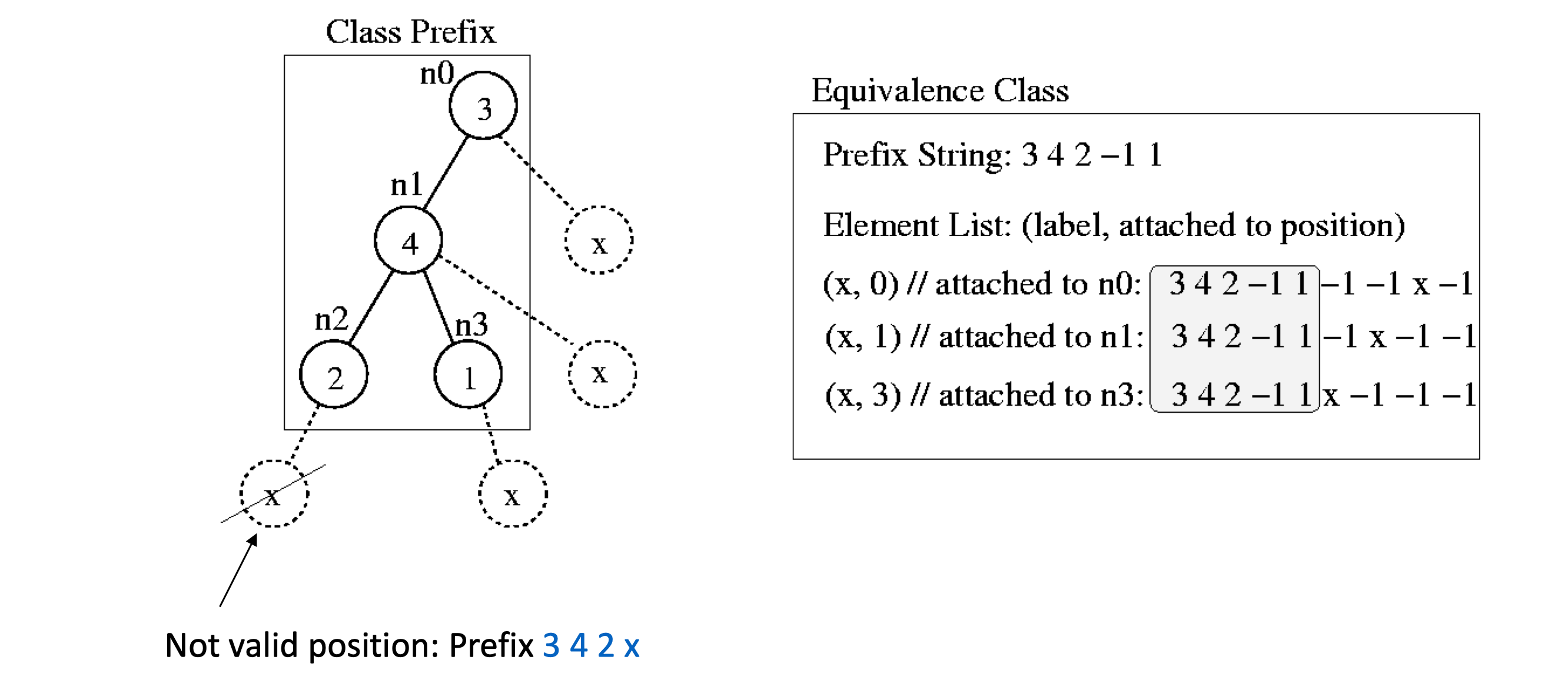
其中 Element List(m, n)中 m 指的是插入值,n 为父节点 id
TreeMiner
当我们用 String 来表示一个一棵树的时候,那么我们就把问题转化成 Sequence Pattern
Mohammed Javeed Zaki 在 2002 年提出 TreeMiner 算法
当父节点包含子节点,则链路可以加长
for each element (x, i) ∈ [P] do
[Px] = ∅;
for each element (y, j) ∈ [P] do
R = {(x, i)⊗(y, j)};
L(R) = {L(x) ∩⊗ L(y)};
if for any R ∈ R, R is frequent then
[Px] = [Px] ∪ {R};
Enumerate-Frequent-Subtrees([Px]);
2
3
4
5
6
7
8
举个 🌰
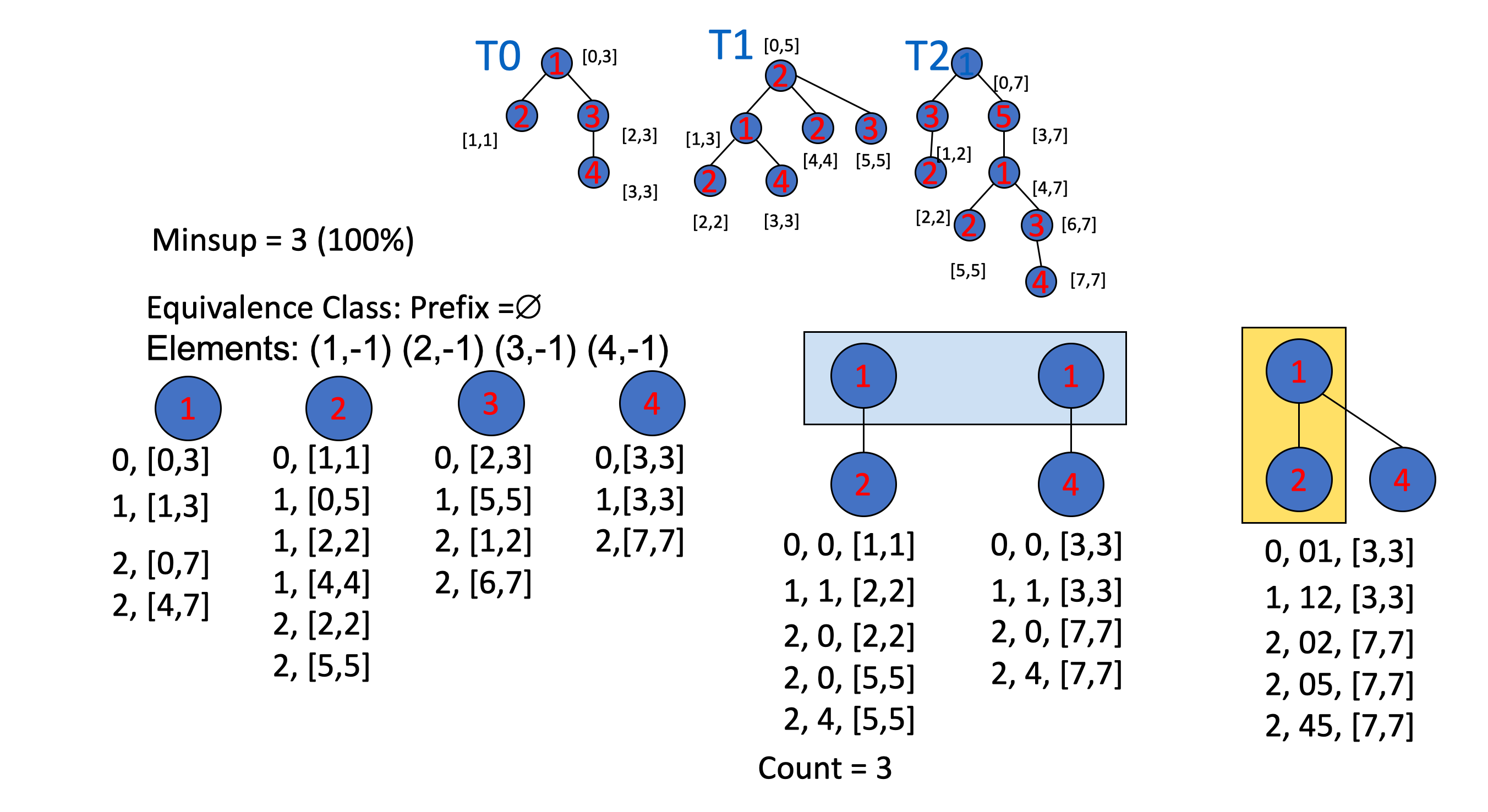
PrefixTreeESpan
上面 TreeMiner 算法类似于 Apriori,属于 DFS 类型的算法
于是很容易想到是否有类似于 FP-tree,PrefixSpan 属于 BFS 的算法
Lei Zou, Yansheng Lu 等人在 2006 年提出 PrefixTreeESpan 算法
从结构上看,从一个节点开始,找所有满足该前缀的结构
如果该结构的个数满足 min_support 则进入下一步
对所有后缀结构首位进行分析,如果满足前缀-后缀首位的结构数大于 min_support 时,则进入下一部
直到没有可分析的结构 则该结构为频繁树
举个栗子
Graph Pattern
如果我们把前面的树结构再进一步推广到图,那么我们要求的就是频繁子图
AGM
AGM = Apriori-base graph Mining
1. S1 数据集中的单个频繁元素;
2. 调用AprioriGraph(D, min_sup, S1)
Procedure AprioriGraph(D, min_sup, Sk)
{ 1. 初始化Sk+1
2. For each 频繁子图 gi ∈Sk
3. For each频繁子图 gj∈Sk
4. For each 通过合并gi和gj形成规模为(k+1)的图g
5. If g是频繁的,并且g不属于 Sk+1
6. 把g插入Sk+1
7. IF Sk+1不为空, then调用AprioriGraph(D, min_sup, Sk+1)
}
2
3
4
5
6
7
8
9
10
11
Akihiro Inokuchi 提出用邻接矩阵存储图数据,通过 basket analysis 得到图的频繁子图
通过定义编码方式把 n×m 的矩阵变成水平扩展的 string
与 Apriori 算法类似,候选频繁子图的生成是根据子图的大小通过水平搜索来进行的
令 Xk 和 Yk 是两个大小为 k 的频繁图 G(Xk)和 G(Yk)的顶点排序的邻接矩阵
如果 G(Xk)和 G(Yk)除了第 k 行和第 k 列的元素之外具有相等的矩阵元素,则它们被连接以生成 Zk+1
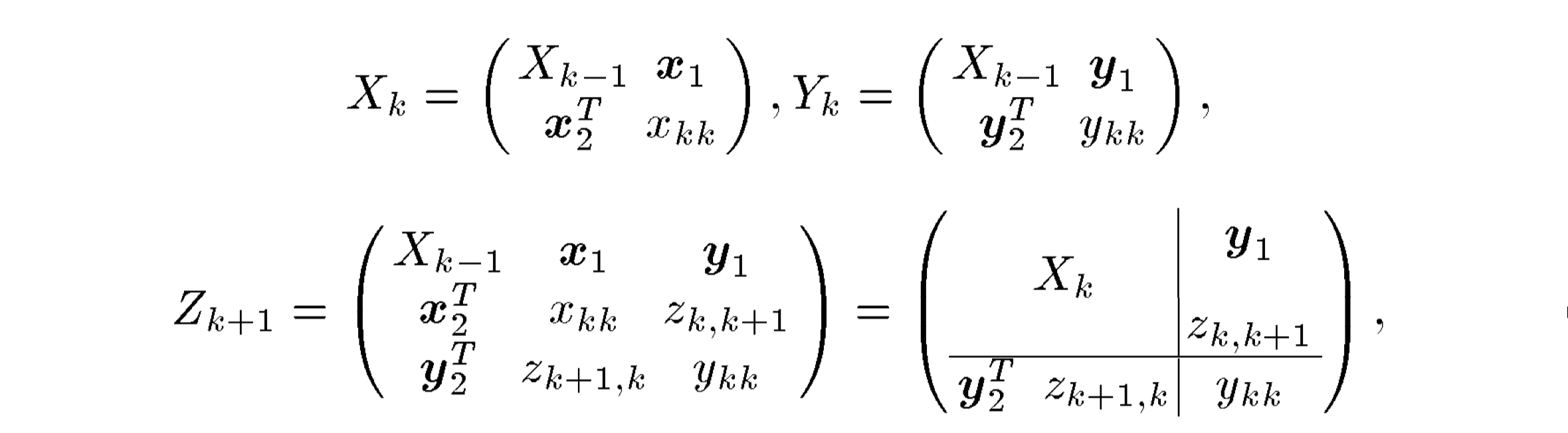
FSG
Framework in FSG:
Step1. Enumerating all frequent single- and double-edge subgraphs;
Step2. Generating all candidate subgraphs whose size is greater than the previous ones by one edge. (Ck)
Step3. Count the frequency for each of these candidates and prune infrequent subgraph patterns. (Fk)
Step4. | Fk |=0, STOP; otherwise k=k+1, and goto Step 2.
2
3
4
5
gSpan
额 最后有点水了 等我消化消化 再来写
参考
- Fast Algorithms for Mining Association Rules
- Mining Frequent Patterns without Candidate Generation
- Mining Sequential Patterns: Generalizations and Performance Improvements
- PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth
- Efficiently Mining Frequent Trees in a Forest
- PrefixTreeESpan: A Pattern Growth Algorithm for Mining Embedded Subtrees
- An Apriori-based Algorithm for Mining Frequent Substructures from Graph Data
- gSpan: Graph-Based Substructure Pattern Mining